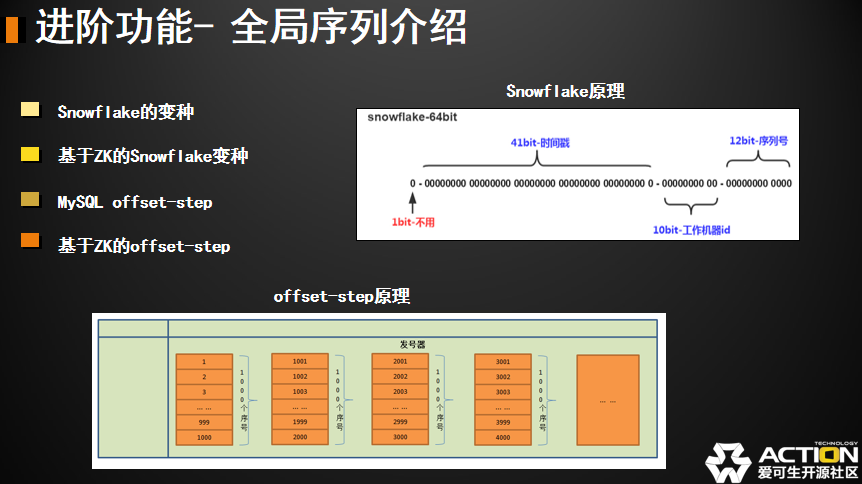
中间还有一个名叫工作机器 ID。这个是为集群设计的,当我的 DBLE 不是单节点部署的,而是集群部署的,或者是负载均衡方式部署的。我需要保证我插入数据库的最终的拆分序列是唯一的,其实我是通过给不同机器或者不同实例标识 ID 来做的,这样的话只要我们单个机器的时间不回退,我的时间戳,我的机器 ID 就能保证我的全局序列是唯一的。但如果你的并发某个峰值真的超过了每毫秒 4096 了,会有重复吗?其实他也不会重复,他会等待。他会直接把峰值满足不了的并发,它会等到这个毫秒过去以后再去下一个毫秒重新去生成新的序列,这种情况下延迟会受到一些影响。