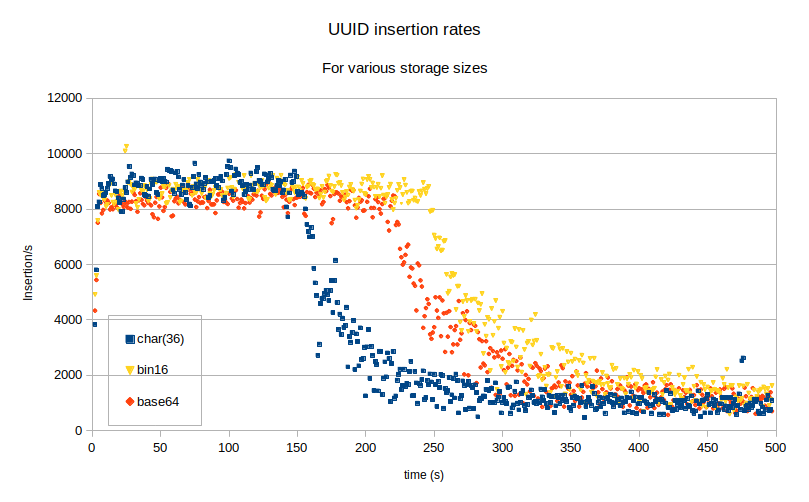
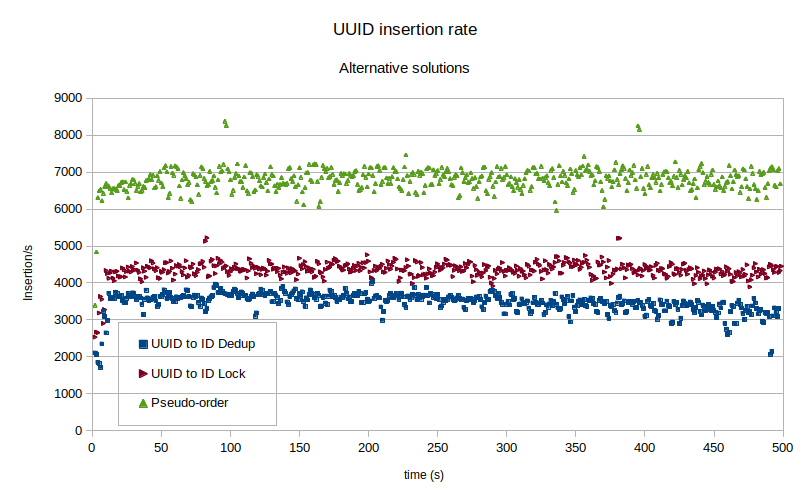
如果我们只是稍微减少值的随机性,以使几个字节的前缀在一个时间间隔内不变,该怎么办?在该时间间隔内,只需要将整个表的一小部分(对应于前缀的基数)存储在内存中,以保存读取的 IOP。这也将增加页面在刷新到磁盘之前接收第二次写入的可能性,从而减少了写入负载。让我们考虑以下 UUID 生成函数:drop function if exists f_new_uuid;
delimiter ;;
CREATE DEFINER=`root`@`%` FUNCTION `f_new_uuid`() RETURNS char(36)
NOT DETERMINISTIC
BEGIN
DECLARE cNewUUID char(36);
DECLARE cMd5Val char(32);
set cMd5Val = md5(concat(rand(),now(6)));
set cNewUUID = concat(left(md5(concat(year(now()),week(now()))),4),left(cMd5Val,4),'-',
mid(cMd5Val,5,4),'-4',mid(cMd5Val,9,3),'-',mid(cMd5Val,13,4),'-',mid(cMd5Val,17,12));
RETURN cNewUUID;
END;;
delimiter ;