因为我这个终端为了清晰,放的有点大,稍微有点乱,我们把这个查询结果简化 select * 改为只需要的列,把横向长度稍微缩小点。不然看起来是有点点累。我们再加一个 \G ,把这个表横过来看一下。
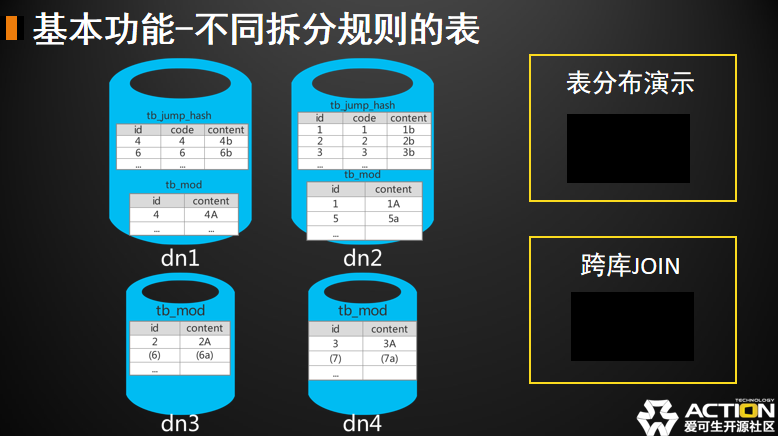
我们可以先看到有 12 行,从头来看,首先我们关注的是前面几行。然后我们发现前四行的内容是一样的,唯一不同的就是 datanode。前四行其他列都是一样的,代表我的查询下发给这四个结点。然后四个节点结果回来以后,在我的中间件进行合并和排序。排序原因这个我们待会再解释。然后会有列的整合和筛选,对于当前这个例子来说其实这个步骤没有实际的工作在做,只是转发给下一步而已。
然后接下来是对第二张表 jump hash 的,SQL 下发到两个节点。然后这两个节点回来以后也会做一个合并。我们可以看到 dn2 后面还有序号,这是为了和前面 dn1 dn2 区别。然后 shuffle field,最后才会去做一个 JOIN,JOIN 就是把刚才 merge shuffle_field 的结果集做一个合并。第三个shuffle field,这里其实仍然是一个转发的过程。最终我才能得到一个JOIN之后的结果。通过这样一个执行计划我们才能去理解跨库 JOIN。
这个例子 JOIN 是完全在 dble 中间件去做的,所以两个节点来说收集和排序,收集好数据以后做合并做 JOIN。