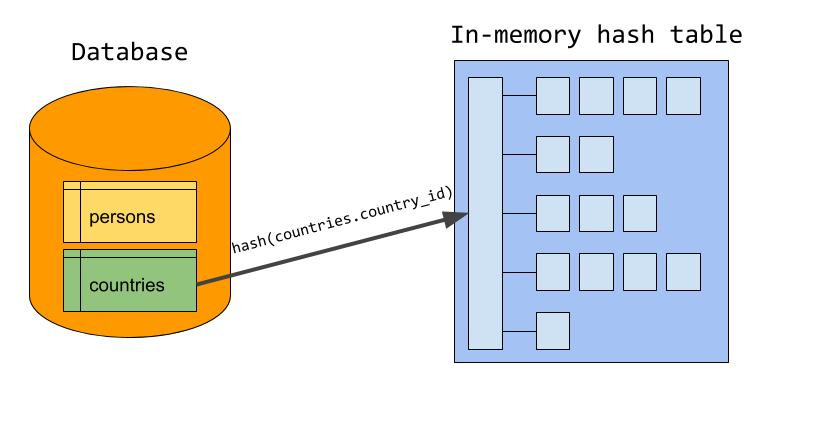
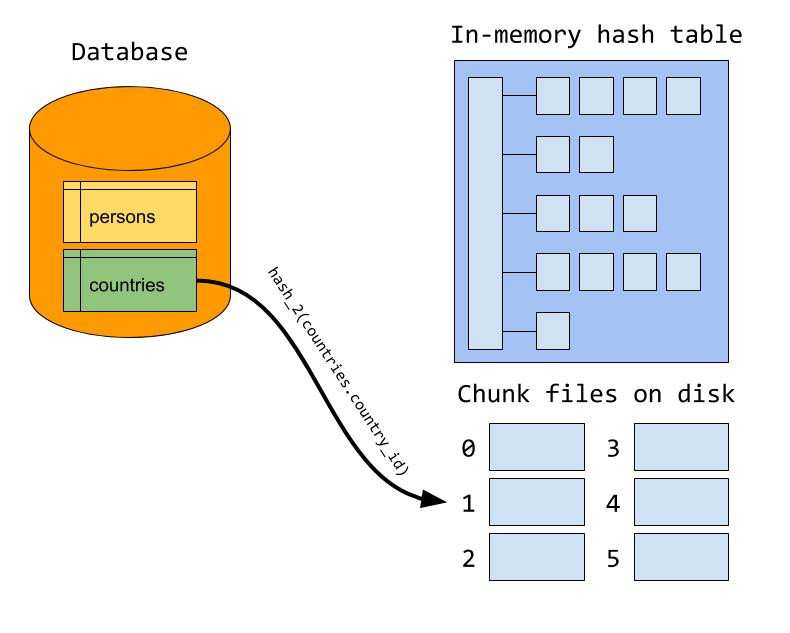
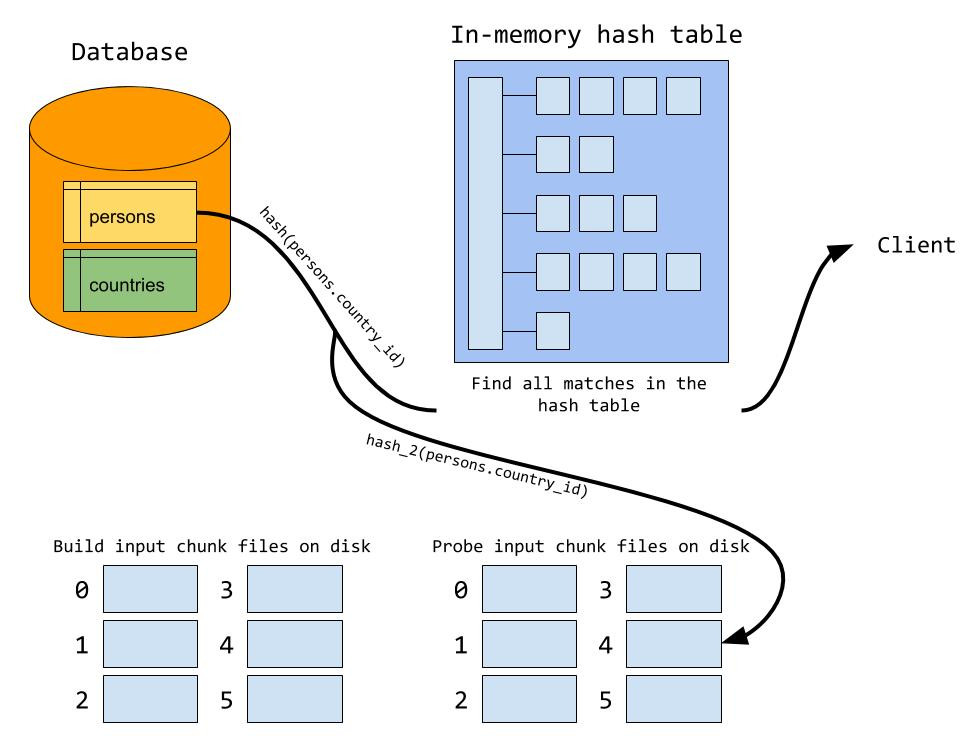
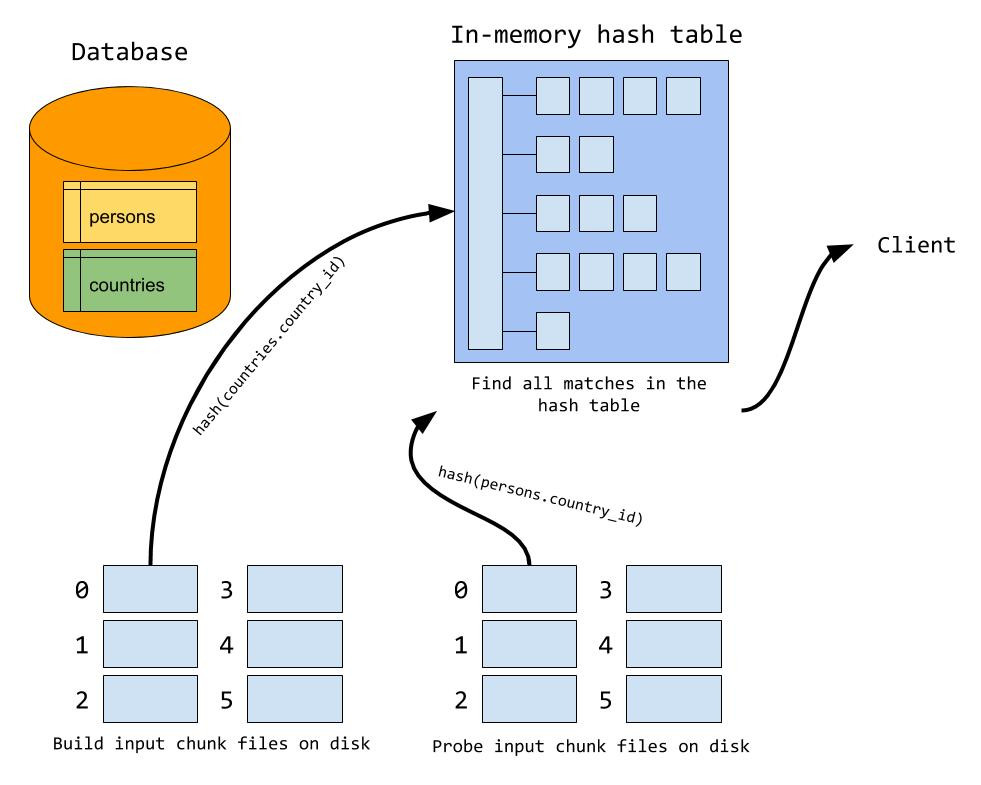
Hash join 默认情况下处于启用状态,因此无需执行任何操作即可使用哈希联接。值得注意的是,Hash join 建立在新的迭代器执行器上,这意味着您必须使用 EXPLAIN FORMAT=tree 来查看是否将使用 Hash join:mysql> EXPLAIN FORMAT=tree
-> SELECT
-> given_name, country_name
-> FROM
-> persons JOIN countries ON persons.country_id = countries.country_id;
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Inner hash join (countries.country_id = persons.country_id) (cost=0.70 rows=1)
-> Table scan on countries (cost=0.35 rows=1)
-> Hash
-> Table scan on persons (cost=0.35 rows=1) |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
通常,如果使用一个或多个等联接条件将表联接在一起,并且联接条件没有索引,则将使用 Hash join。如果索引可用,则 MySQL 倾向于使用带有索引查找的嵌套循环。我们引入了一个新的优化器开关,使您可以对任何查询禁用 Hash join:mysql> SET optimizer_switch="hash_join=off";
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN FORMAT=tree
-> SELECT
-> given_name, country_name
-> FROM
-> persons JOIN countries ON persons.country_id = countries.country_id;
+----------------------------------------+
| EXPLAIN |
+----------------------------------------+
| |
+----------------------------------------+
1 row in set (0.00 sec)
禁用 Hash join 后,MySQL 将退回到块嵌套循环,从而使用旧的执行程序(迭代器执行程序不支持块嵌套循环)。此开关使比较 Hash join 和块嵌套循环的性能变得容易。
如果由于构建输入太大而导致无法容纳在内存中并使用磁盘。则可以增加连接缓冲区的大小。与块嵌套循环相反,Hash join 将递增地分配内存,这意味着它将永远不会使用超出其需求的内存。因此,使用 Hash join 时,使用较大的连接缓冲区大小更安全。