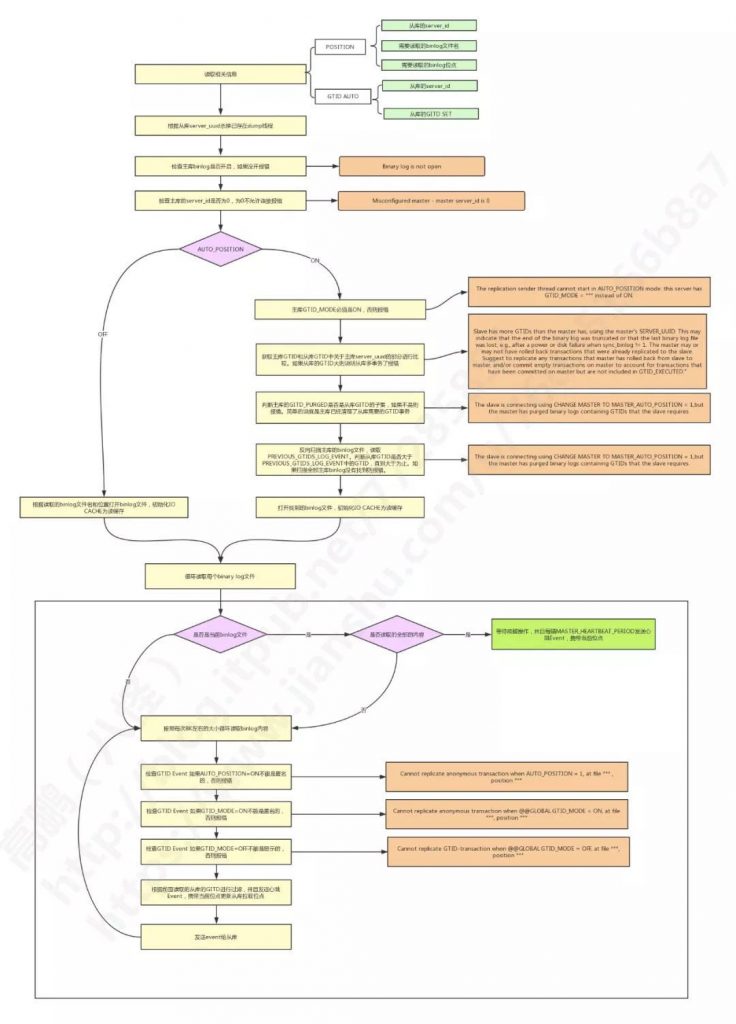
4、观察现象
大概每 10 秒会生成一个 relay log 文件如下:-rw-r----- 1 mysql mysql 500 2019-09-27 23:48:32.655001361 +0800 relay.000142
-rw-r----- 1 mysql mysql 500 2019-09-27 23:48:42.943001355 +0800 relay.000143
-rw-r----- 1 mysql mysql 500 2019-09-27 23:48:53.293001363 +0800 relay.000144
-rw-r----- 1 mysql mysql 500 2019-09-27 23:49:03.502000598 +0800 relay.000145
-rw-r----- 1 mysql mysql 500 2019-09-27 23:49:13.799001357 +0800 relay.000146
-rw-r----- 1 mysql mysql 500 2019-09-27 23:49:24.055001354 +0800 relay.000147
-rw-r----- 1 mysql mysql 500 2019-09-27 23:49:34.280001827 +0800 relay.000148
-rw-r----- 1 mysql mysql 500 2019-09-27 23:49:44.496001365 +0800 relay.000149
-rw-r----- 1 mysql mysql 500 2019-09-27 23:49:54.789001353 +0800 relay.000150
-rw-r----- 1 mysql mysql 500 2019-09-27 23:50:05.485001371 +0800 relay.000151
-rw-r----- 1 mysql mysql 500 2019-09-27 23:50:15.910001430 +0800 relay.000152
2019-10-08T02:27:24.996827+08:00 217 [Note] While initializing dump thread for slave with UUID <010fde77-2075-11e9-ba07-5254009862c0>, found a zombie dump thread with the same UUID. Master is killing the zombie dump thread(216).
2019-10-08T02:27:24.998297+08:00 217 [Note] Start binlog_dump to master_thread_id(217) slave_server(953340), pos(, 4)
2019-10-08T02:27:35.265961+08:00 218 [Note] While initializing dump thread for slave with UUID <010fde77-2075-11e9-ba07-5254009862c0>, found a zombie dump thread with the same UUID. Master is killing the zombie dump thread(217).
2019-10-08T02:27:35.266653+08:00 218 [Note] Start binlog_dump to master_thread_id(218) slave_server(953340), pos(, 4)
2019-10-08T02:27:45.588074+08:00 219 [Note] While initializing dump thread for slave with UUID <010fde77-2075-11e9-ba07-5254009862c0>, found a zombie dump thread with the same UUID. Master is killing the zombie dump thread(218).
2019-10-08T02:27:45.589814+08:00 219 [Note] Start binlog_dump to master_thread_id(219) slave_server(953340), pos(, 4)
2019-10-08T02:27:55.848558+08:00 220 [Note] While initializing dump thread for slave with UUID <010fde77-2075-11e9-ba07-5254009862c0>, found a zombie dump thread with the same UUID. Master is killing the zombie dump thread(219).
2019-10-08T02:27:55.849442+08:00 220 [Note] Start binlog_dump to master_thread_id(220) slave_server(953340), pos(, 4)