答:可以将一台服务器设置为主服务器,并将所有写入指向它。然后在允许的范围内配置尽可能多的从服务器,并在主服务器和从服务器之间分配读操作。还可以使用 –skip-innodb 选项启动从服务器,启用 low_priority_updates 系统变量,并将 delay_key_write 系统变量设置为 ALL,用以提升从服务器端速度。
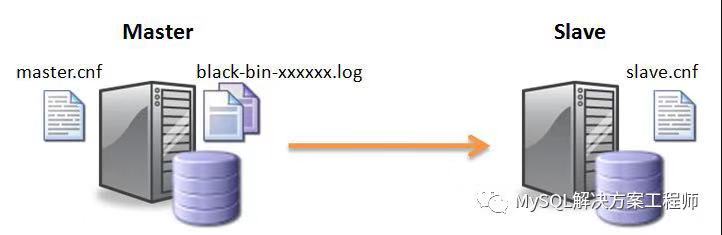
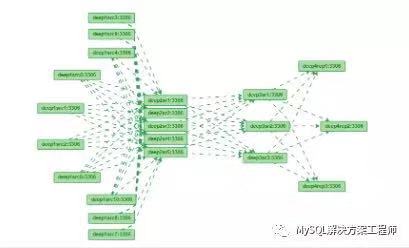
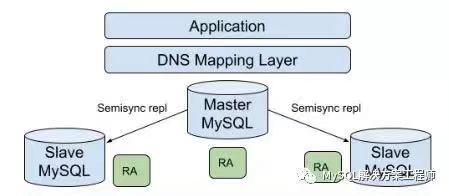
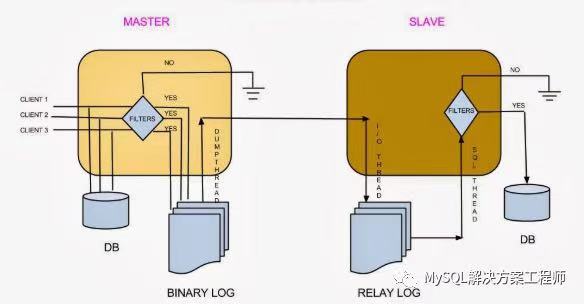
对于处理频繁读取和少量写入的系统,MySQL 复制是最有效的。理论上,使用一主多从的设置,可以添加更多的从服务器来扩展系统,直到耗尽网络带宽,或者写入负载增长到主服务器无法处理它的程度。
如果想要确定使用多少台从服务器可以提升性能,用户必须了解系统的查询模式,并对主服务器和从服务器上的读写吞吐量之间的关系进行基准测试。
假设系统负载由 10% 的写入和 90% 的读取组成,我们通过基准测试确定 R =1200 – 2 *W。( R 和 W 代表每秒的读取和写入次数)换句话说,系统可以在不进行写入的情况下每秒读取 1200 次,平均的写入速度是平均读取速度的两倍时长,并且关系是线性的。假设主服务器和每个从服务器的性能相同,我们有一个主服务器和 N 个从服务器。每台服务器计算下面的等式:
R = 1200 – 2 * W
R = 9 * W/ (N + 1) (10%写,90%读。读取被拆分,写入被复制到所有从服务器。)
9 * W / (N + 1) + 2 * W = 1200
W = 1200 / (2 + 9/(N + 1))
最后一个等式表示了 N 个从服务器的最大写入次数,给定最大可能的读取速率为每秒 1,200 次,每次写入的读取次数为 9 次。
通过分析可以得出以下结论:
如果 N=0,表示没有使用复制功能,系统每秒可以处理 1200/11=109 次写操作。
如果 N=1,系统每秒可以处理 184 次写操作。
如果 N=8,系统每秒可以处理 400 次写操作。
如果 N=17,系统每秒可以处理 480 次写操作。
当 N 趋于无穷大时,我们可以非常接近每秒 600 次写操作,将系统吞吐量提高约5.5倍。然而,在只有 8 台服务器的情况下,我们将其增加了近 4 倍。
这些计算假定网络带宽是无限的,因而忽略了其他几个可能对系统很重要的因素。在大多数情况下,用户可能无法执行类似的计算,但该计算可以准确地预测如果添加 N 个从服务器将会在系统上发生什么。
考虑以下问题可以帮助决定复制是否会改善系统的性能,以及在多大程度上改善系统的性能:
a. 系统的读/写比率是多少?
b. 如果减少读操作,一台服务器可以处理多少写负载?
c. 网络上有多少个从服务器可用带宽?