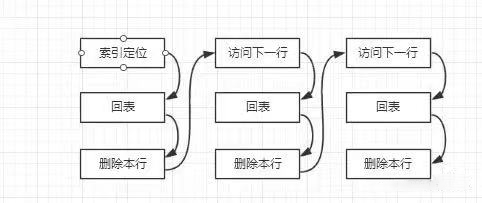
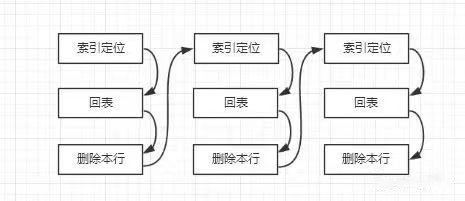
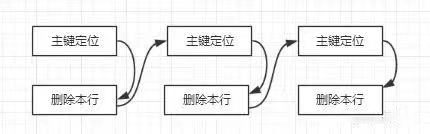
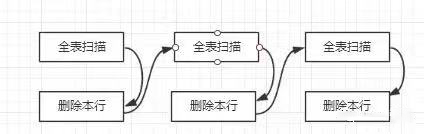
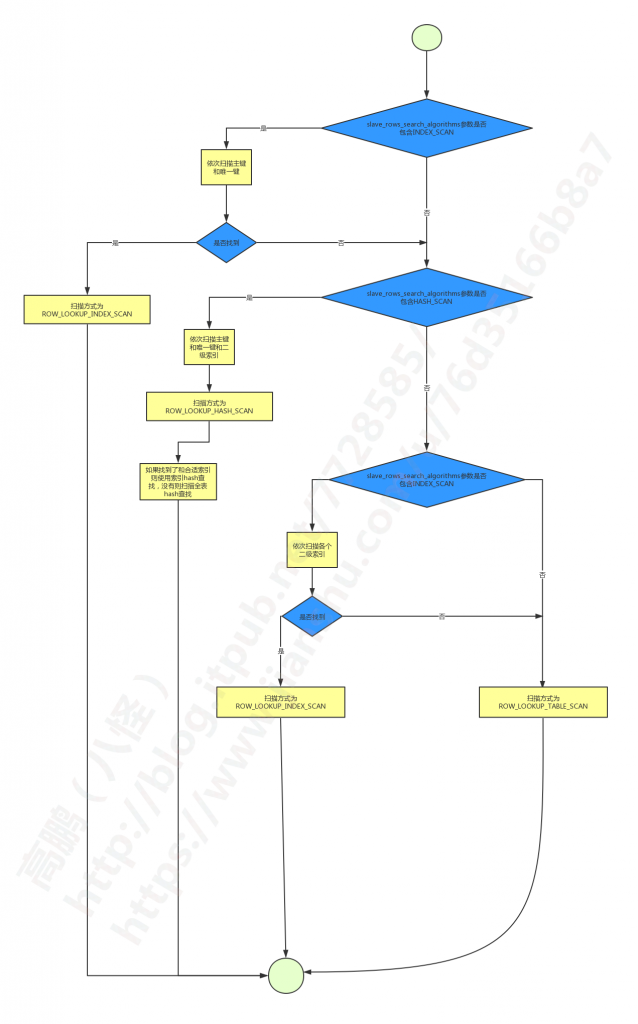
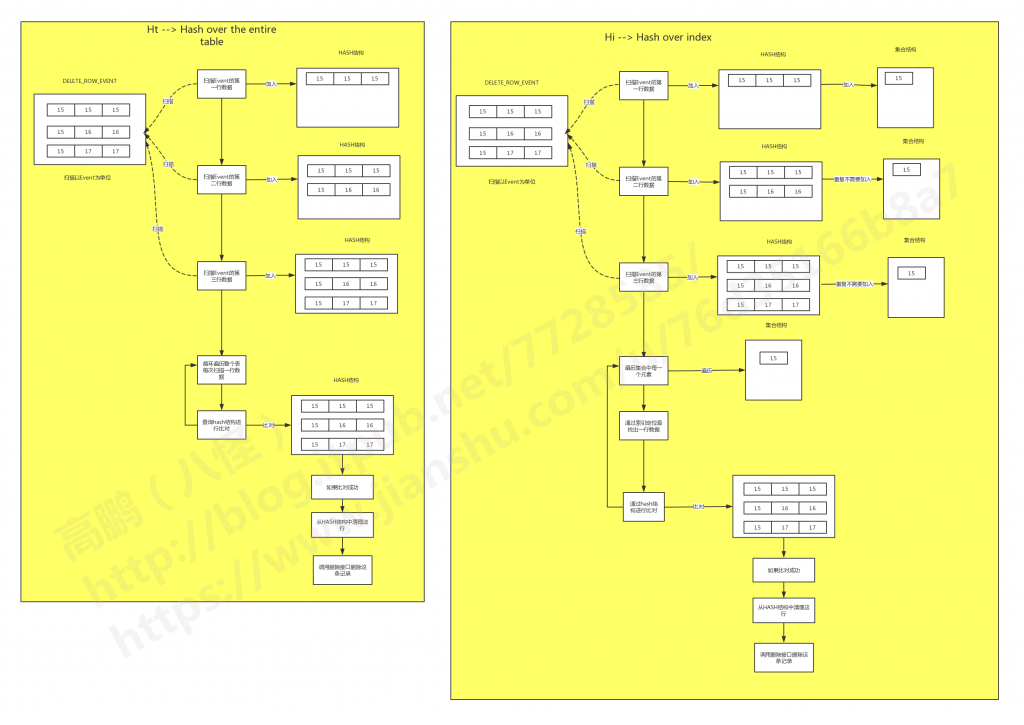
在源码中有如下的说明,当然官方文档也有类似的说明:/*
Decision table:
- I --> Index scan / search
- T --> Table scan
- Hi --> Hash over index
- Ht --> Hash over the entire table
|--------------+-----------+------+------+------|
| Index\Option | I , T , H | I, T | I, H | T, H |
|--------------+-----------+------+------+------|
| PK / UK | I | I | I | Hi |
| K | Hi | I | Hi | Hi |
| No Index | Ht | T | Ht | Ht |
|--------------+-----------+------+------+------|
*/