摘要:
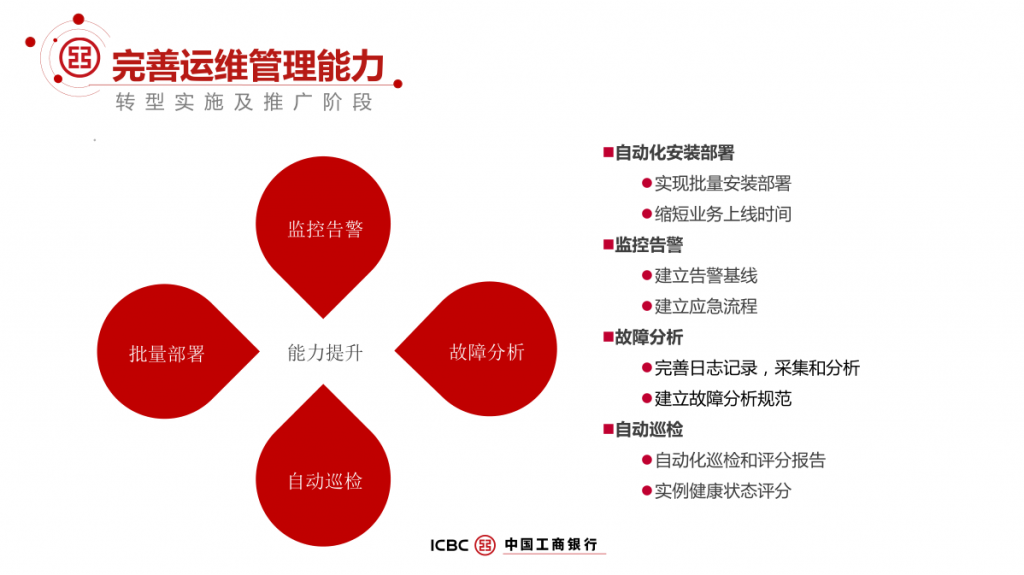
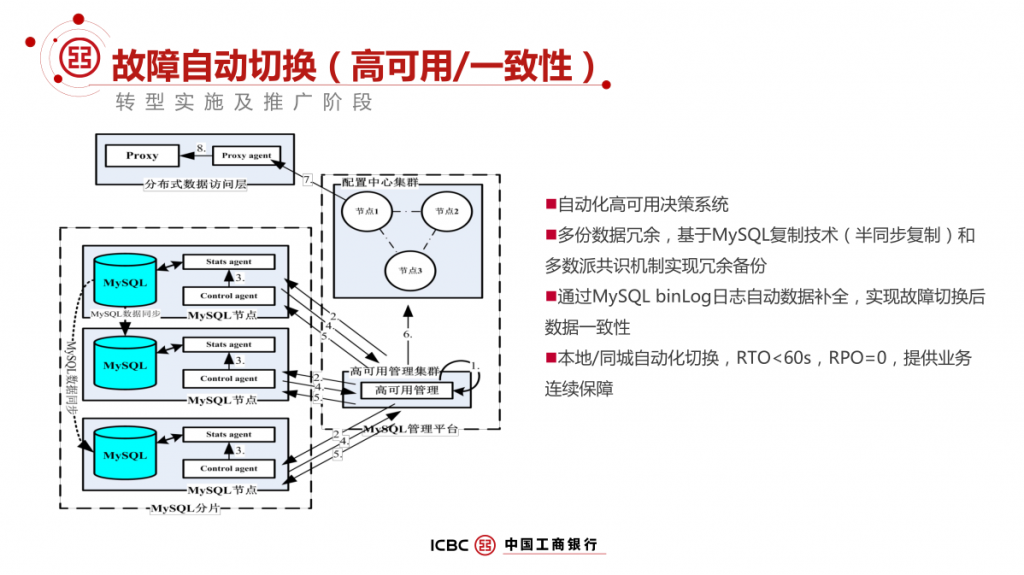
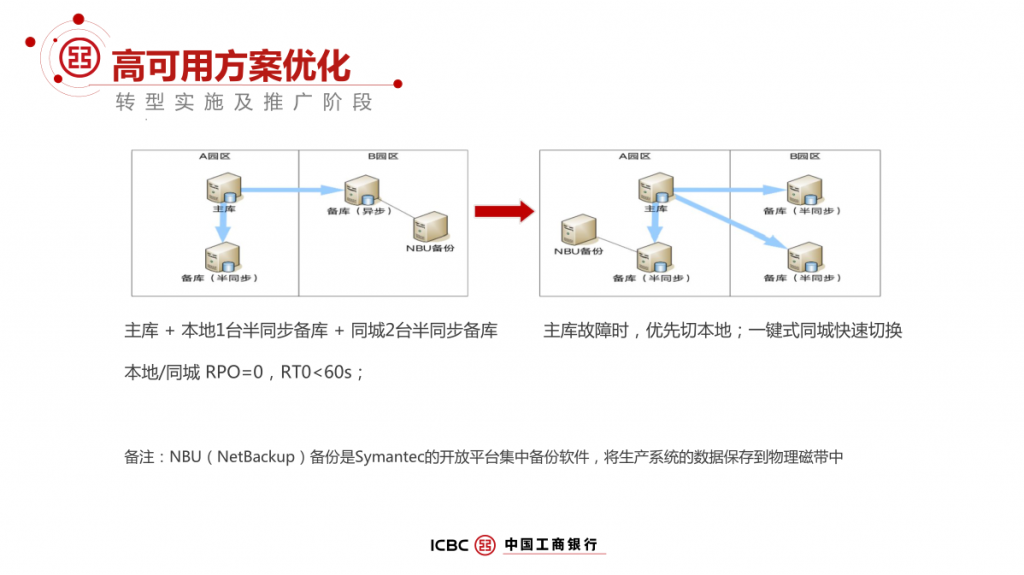
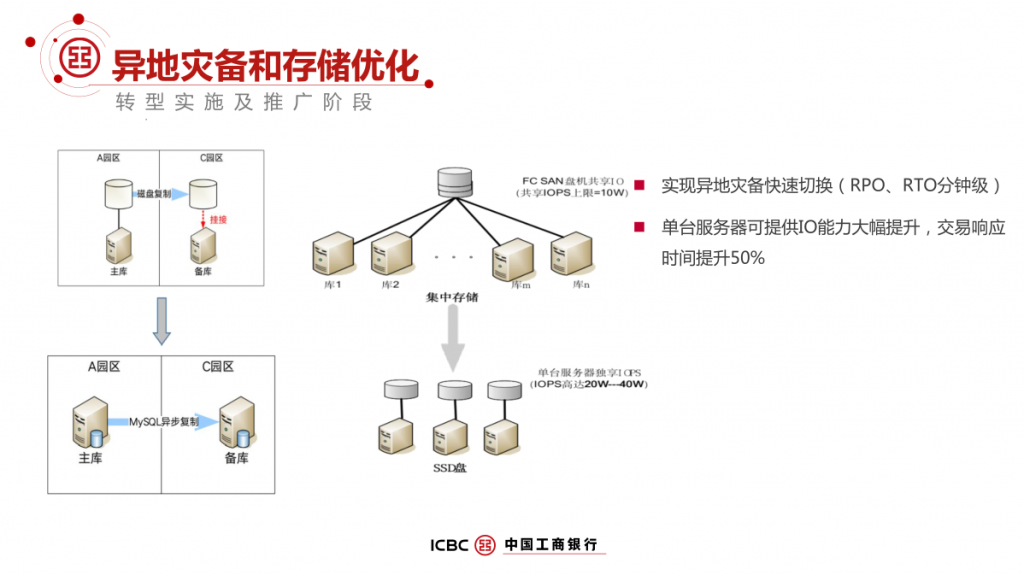
本文根据DTCC数据库大会分享内容整理而成,将介绍工行 IT 架构转型中传统 OLTP 数据库架构面临的挑战和诉求,构建基于 MySQL 分布式企业级解决方案实践历程,包括技术选择、高可用设计、两地三中心容灾、运维管理、资源使用效率等方面的思考和实践经验,同时也介绍了工行转型的成效以及对后续工作的一些思考。
关键词:
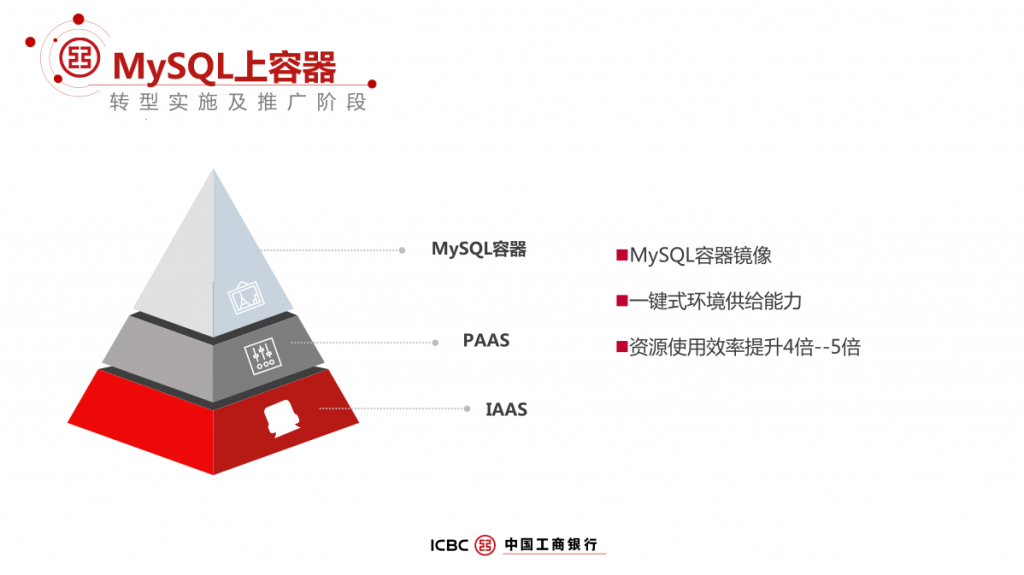
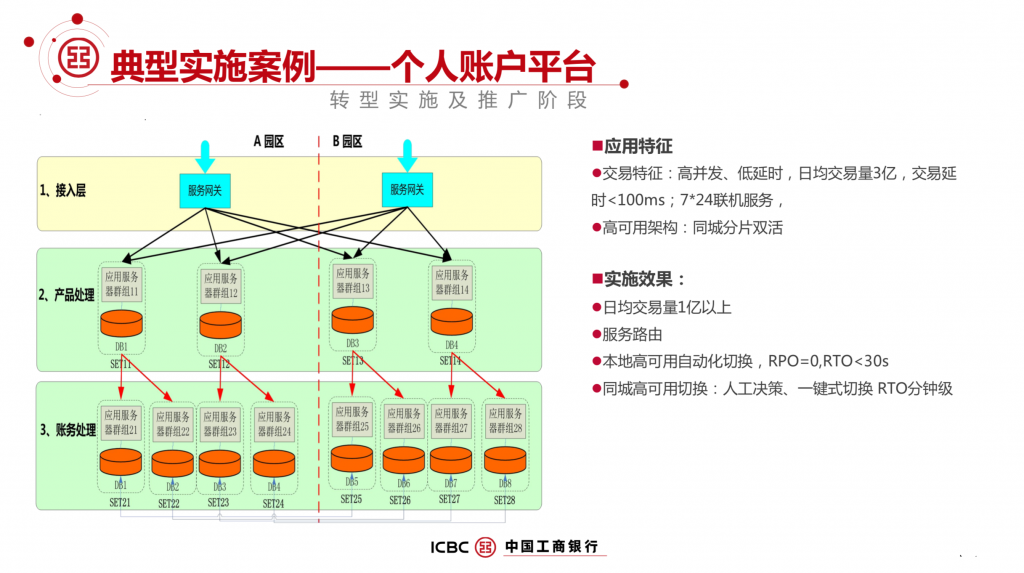
拥抱开源;MySQL; 高可用; 分布式;数据拆分; DBLE; 管理平台;灾备;容器;
演讲者介绍:
林承军,中国工商银行软件开发中心高级经理,多年来一直从事开放平台相关技术研究及实施工作,多次参与工行重点项目的原型技术研究、IT 架构转型及优化提升,在分布式、高可用架构、数据高效访问领域有丰富的实施经验。近年来,牵头 MySQL/分布式数据库团队工作,借鉴和引入业界成功经验,通过自主研发 技术引入,迅速形成基于开源 MySQL 的企业级应用研发能力,初步建立了企业级解决方案,推动工行开放平台 OLTP 数据库转型的实施。