通过一个故障案例,理解 ClickHouse 分布式机制。
作者:张宇,爱可生DBA,负责数据库运维和故障分析。擅长 ClickHouse、MySQL、Oracle,爱好骑行、AI、动漫和技术分享。
爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
本文约 1500 字,预计阅读需要 5 分钟。
业务场景
在日常运维的某个系统下,有一套 4 分片 3 副本的高可用分布式的 ClickHouse 集群。当前分片的每个节点的数据量为 5.6TB。
故障背景
监控发现其中的一个节点无法使用,后续排查发现 5 块磁盘已经损坏,Raid10 也无法保证数据完整,导致数据目录全部重新换成新的磁盘,而且使用的是传统机械盘,速度慢。现在联系厂商更换磁盘,需要停用此节点,等厂商更换完毕之后,需要配合恢复数据。
恢复思路
ClickHouse 的集群是一个分布式的集群,每个分片的数据不同,所有分片的数据加起来才是一份完整的数据,每个分片副本的数据是相同的,这就是 ClickHouse 数据的高可用。
本次也是非常典型的故障,硬件做了 Raid10,但是 Raid10 磁盘基本上全部坏掉了,导致 Raid10 离线也无法使用,最后更换了所有的磁盘,导致整个数据目录变成了空的。
因为此副本为一个分片中的其中一个副本,还有其他两个副本在线,所以业务使用无影响,而且我们可以通过其他副本里面的数据开始恢复此副本的数据。
恢复的基本原理: 同一个分片里面 Zookeeper 路径相同的表,但是副本名不同。数据是会自动验证同步的,所以我们只需要重建表,并且保证 Zookeeper 地址一致,副本名不一致,就会自动开始同步数据,直到两个副本数据完全一致。
副本之间是如何同步数据的呢?
Zookeeper 里面存放了副本数据文件 parts 的路径。如果当前副本没有这些 parts 就会通过 Zookeeper 得到其他副本的 parts 路径,然后通过 9009 端口进行数据文件的传输,然后恢复数据。
如下是官方的原理图:

查看节点是否存在残留数据
- clickhouse-1:同一个分片正常副本
- clickhouse-2:坏掉的副本
shell> clickhouse-client --password
clickhouse-2> show databases;
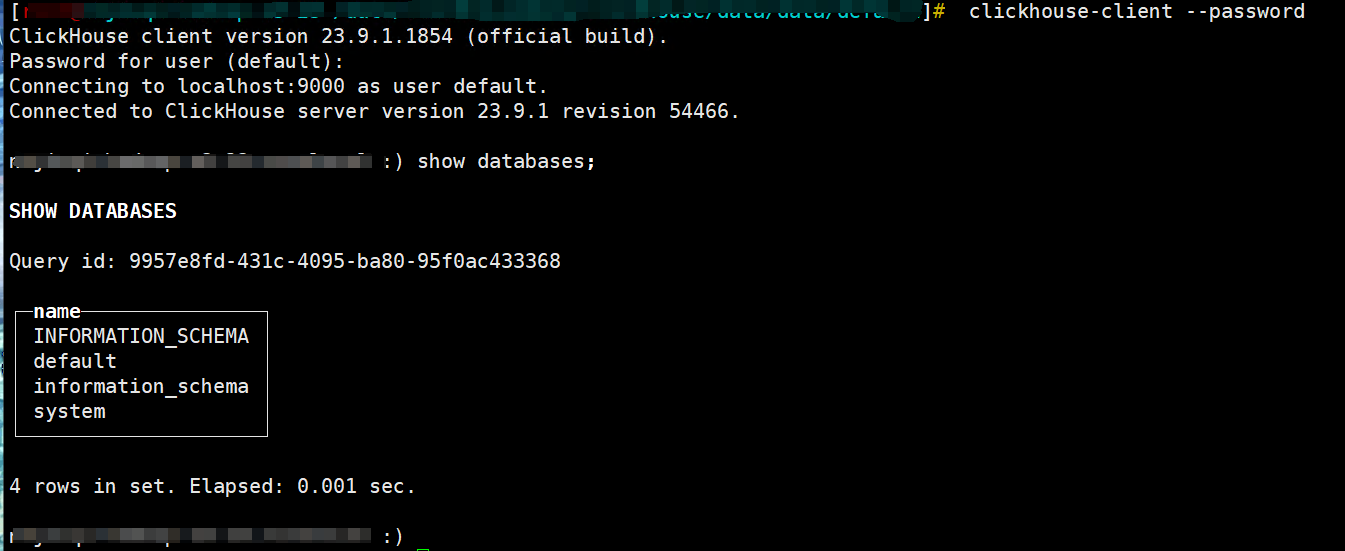
经过确认无残留数据。
查看当前节点的副本
clickhouse-2>select * from system.clusters;
is_local 为 1 就是当前登录的节点。

恢复数据
因为旧节点磁盘损坏,所以需要在它的其他副本得到这些信息,然后到损坏的节点执行:
shell> clickhouse-client --password --host=xxx.xxx.77.30 --port=9000
clickhouse-1>select database,table,replica_is_active from system.replicas;

第三副本的表全部都无法访问。
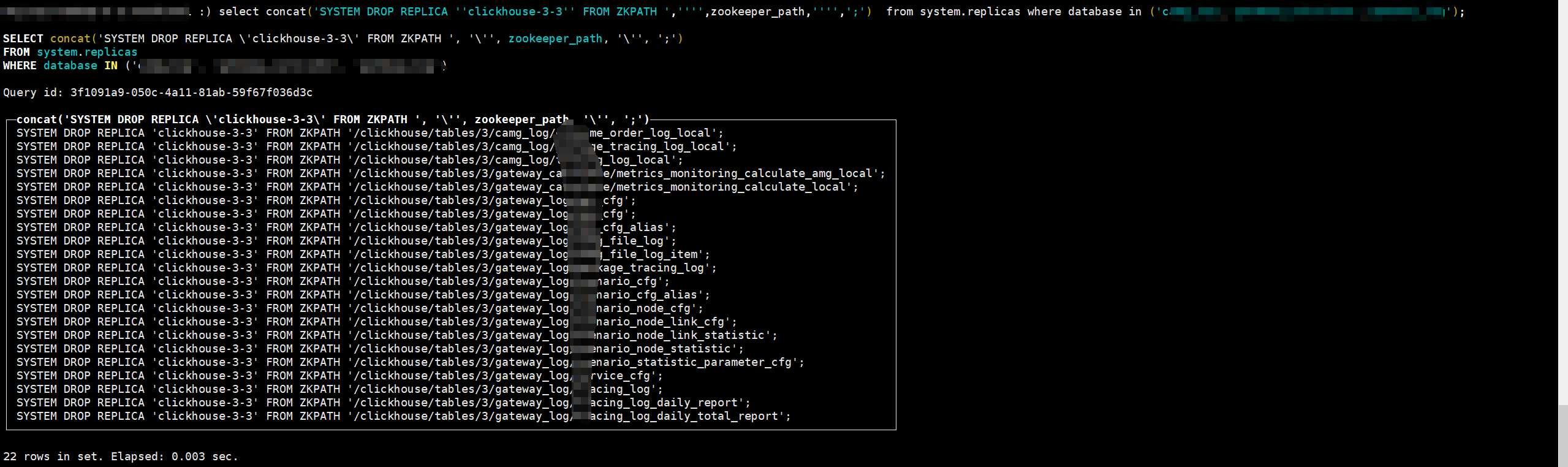
导出清理 Zookeeper 元数据的 SQL 语句。
因为只是磁盘坏了,本地数据没有了,但是 Zookeeper 里面的数据还存在,如果不清理,重建表的时候会导致元数据冲突无法创建表。
创建清理 Zookeeper 元数据的 SQL 文件。
shell> vim clear_zk.sql

清理 Zookeeper 的元数据。
shell> clickhouse-client --password --port 9000 --multiquery < clear_zk.sql 2&>1 clear.log7

导出表结构。
clickhouse-1>select zookeeper_path ,create_table_query from system.tables a right join system.replicas b on a.name=b.table where a.database in ('xxx','xxx','xxx') ;

创建所有数据库。
clickhouse-2>create database xxx;

创建建表的 SQL 文件。
PS:要注意这个标红的一定要和 Zookeeper 元数据的地址一样,就是上面导出来的时候第一列就是 Zookeeper 的元数据的地址,一定要好好验证,有些客户建表是存在uuid的,如果存在uuid一定要比对保证地址一样不然无法恢复数据。
ReplicatedReplacingMergeTree(‘/clickhouse/tables/3/xxxx/xxxxx’, ‘{replica}’, created_time)
shell> vim init_table.sql

重建表并确认表是否同步数据。
shell>clickhouse-client --password --port 9000 --multiquery < init_table.sql

检查表的数据是否正确这里总共 22 张本地表,存于在 3 个库。

经过验证已经全部重建完毕,现在验证数据是否传输。
clickhouse-2>use database
clickhouse-2>select * from xxxx limit 5;

检查磁盘的同步情况。
shell>df -h
数据一直同步每分钟数据量大概 10GB 的速度同步回来。

恢复分布式总表
shell>clickhouse-client --password --host=xxx.xxx.77.30 --port=9000
clickhouse-1>select create_table_query from system.tables a where a.database in ('xxx','xxx','xxx') and engine='Distributed';

创建分布式表的初始化 SQL 文件。
shell>vim init_d_table.sql

同步。
shell>clickhouse-client --password --port 9000 --multiquery < init_d_table.sql

检查分布式总表是否全部创建总共 22 张。
clickhouse-2>select count(1) from system.tables a where a.database in ('xxx','xxx','xxx') and engine='Distributed';

查询分布式总表看看是否有数据。

通过其他副本验证同步复制关系是否正常
shell>clickhouse-client --password --host=xxx.xxx.77.30 --port=9000
clickhouse-1>select database,table,replica_is_active from system.replicas;

已经通过验证所有表已经全部恢复同步。
总结与启示
本次 ClickHouse 数据恢复案例展示了以下具体技术关键点:
- 数据冗余备份:
- 确保每个分片有多个副本,防止单点故障导致数据丢失。
- 掌握 ClickHouse 和 Zookeeper 同步机制:
- 了解如何通过 Zookeeper 获取其他副本的 parts 路径,并使用端口
9009进行数据传输恢复。
- 了解如何通过 Zookeeper 获取其他副本的 parts 路径,并使用端口
- 清理 Zookeeper 元数据:
- 在磁盘损坏后,需清理 Zookeeper 中的元数据,以避免重建表时发生元数据冲突。
- 详细的恢复操作步骤:
- 导出表结构并创建数据库。
- 使用create_table_query重建表并确认数据同步。
- 检查磁盘同步情况,确保数据正确恢复。
- 持续监控与维护:
- 定期检查系统状态,及时发现并解决潜在问题,确保系统高可用性。
这些经验和具体操作步骤能有效提高系统的可靠性和运维效率,增强应对突发故障的能力。