作者:胡呈清
爱可生 DBA 团队成员,擅长故障分析、性能优化,个人博客:https://www.jianshu.com/u/a95ec11f67a8,欢迎讨论。
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
如果要使用 Zabbix 监控使用 TiDB,需使用 HTTP agent ,主动调用 TiDB 监控接口获取监控数据,然后配置数据预处理:选择使用 Prometheus pattern 或者 Prometheus to JSON 方法,但是这两个功能是在 Zabbix4.2 中加入的,Zabbix4.0.x 没有这个功能(即使是最新的 zabbix4.0.35):
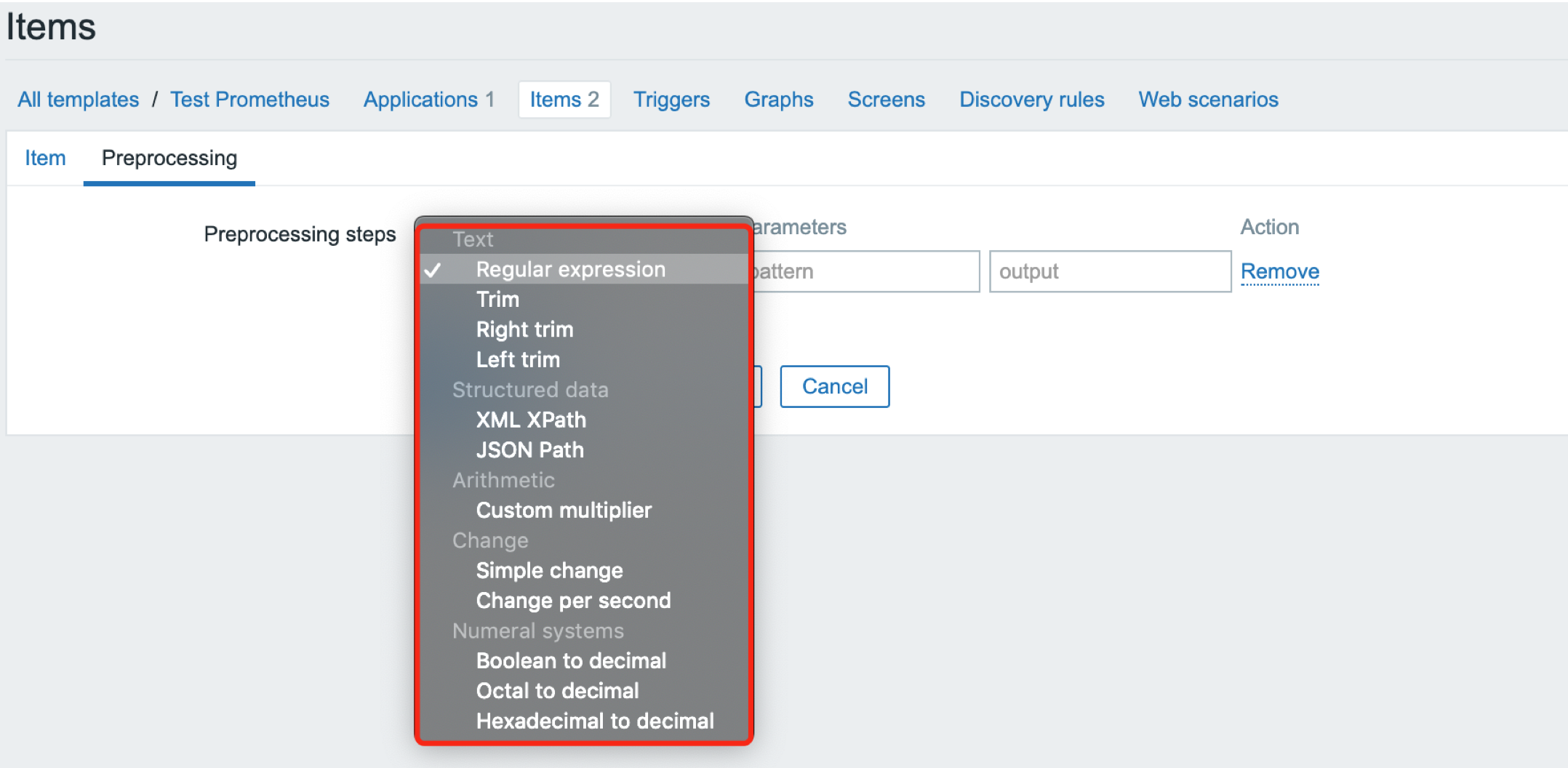
所以在没法升级到 Zabbix5.4 时,我们可以在大于 4.2 的版本上手工创建监控模板,以下演示环境为 Zabbix5.0.5。
TiDB 监控接口
在开始前,需要先了解 TiDB 的监控接口:https://docs.pingcap.com/zh/tidb/v5.1/tidb-monitoring-api
示例:
curl http://127.0.0.1:10080/metrics > /tmp/tidb_metics
参考TiDB 官网上的告警规则(https://docs.pingcap.com/zh/tidb/v5.1/alert-rules)中的第一条告警规则:
increase(tidb_session_schema_lease_error_total{type="outdated"}[15m]) > 0
这个是 prometheus 的语法,我们只需要知道 tidb_session_schema_lease_error_total 是 metrics name 就行,然后我们去监控数据中找到这个 metric(TiDB的不同版本metric可能不一样,示例中的 metric 在4.0.10中就没有,在5.1中有):
[root@localhost tmp]# grep tidb_session_schema_lease_error_total /tmp/tidb_metics
# HELP tidb_session_schema_lease_error_total Counter of schema lease error
# TYPE tidb_session_schema_lease_error_total counter tidb_session_schema_lease_error_total{type="outdated"} 2
其数据格式为:
说明
以“# HELP”开头,是对这个 metric 的说明
类型
以“# TYPE”开头,表示这个 metric 的数据类型,一共有4种:
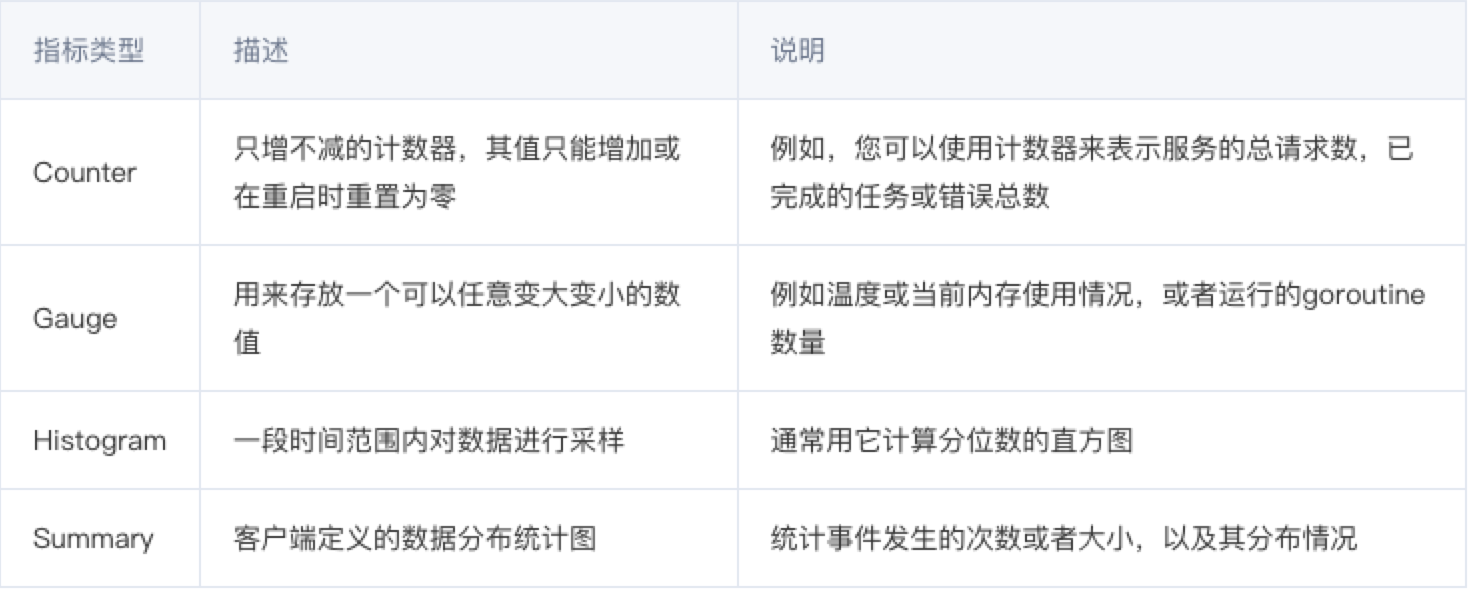
数据
这里要注意的就是上述示例中的“type”标签,有些 metric 会有多个标签,我们可以根据标签取其中的几个(比如需求是计算所有Select、Update、Insert命令的总耗时):
tidb_server_handle_query_duration_seconds_sum{sql_type="Begin"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="Commit"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="Delete"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="Execute"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="Insert"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="Replace"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="Rollback"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="Select"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="Set"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="Show"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="Update"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="Use"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="general"} 0
tidb_server_handle_query_duration_seconds_sum{sql_type="internal"} 12260.158577597258
接下来介绍如何在Zabbix中手工添加 TiDB 监控。
创建 items
item 就是监控项,那我们要监控 TiDB 的哪些指标呢?可以参考官方告警规则,需要告警的监控项一定是最优先的。
-
创建 master item
参数如下图,红色标记是重点。这个 item 定义了调用 TiDB Server 的 metrics 接口获取到所有监控指标的数据:

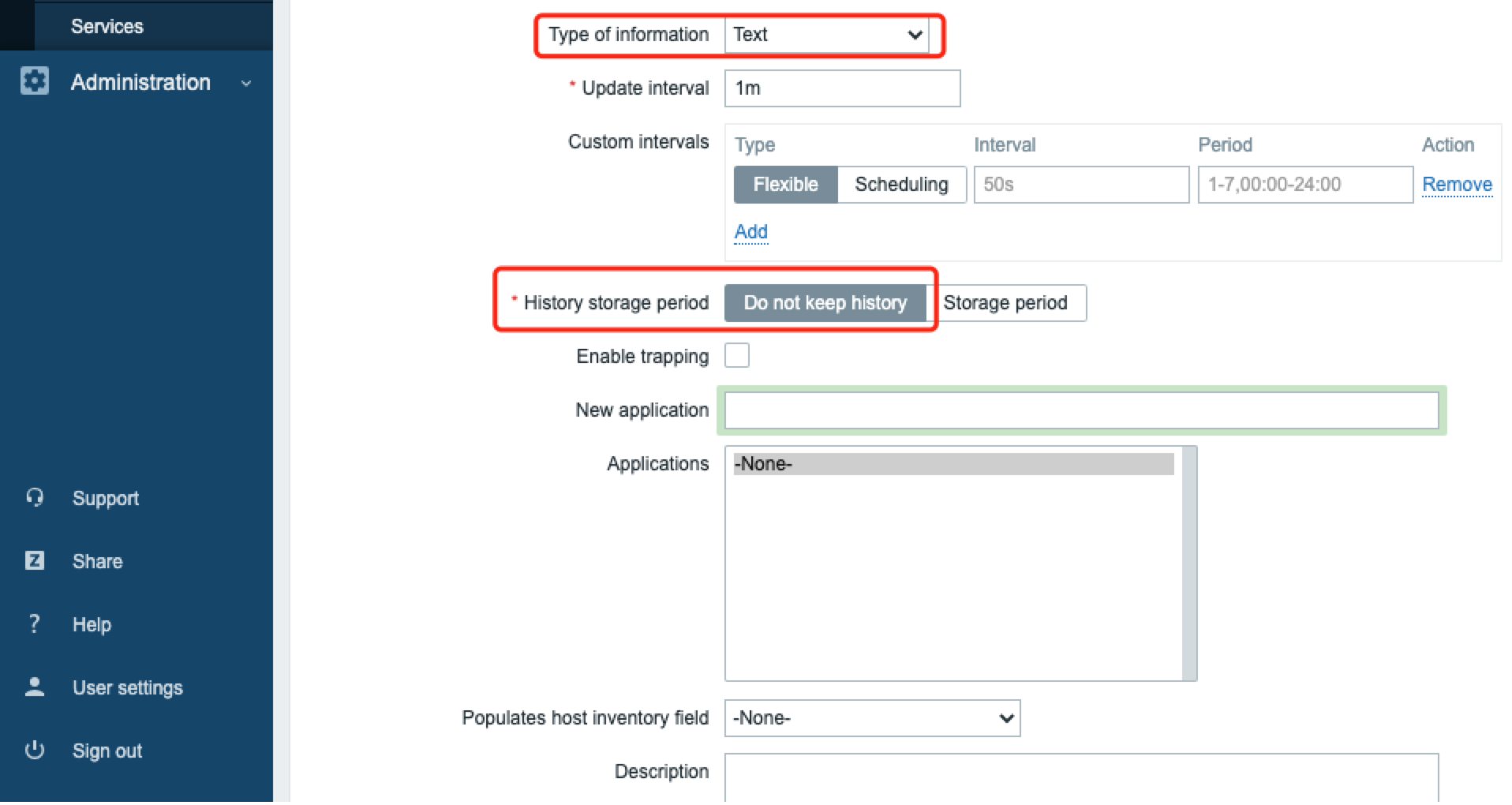
注意取到的数据格式为 Text,需要在“Preprocession”(数据预处理)中定义转化成 JSON 格式:
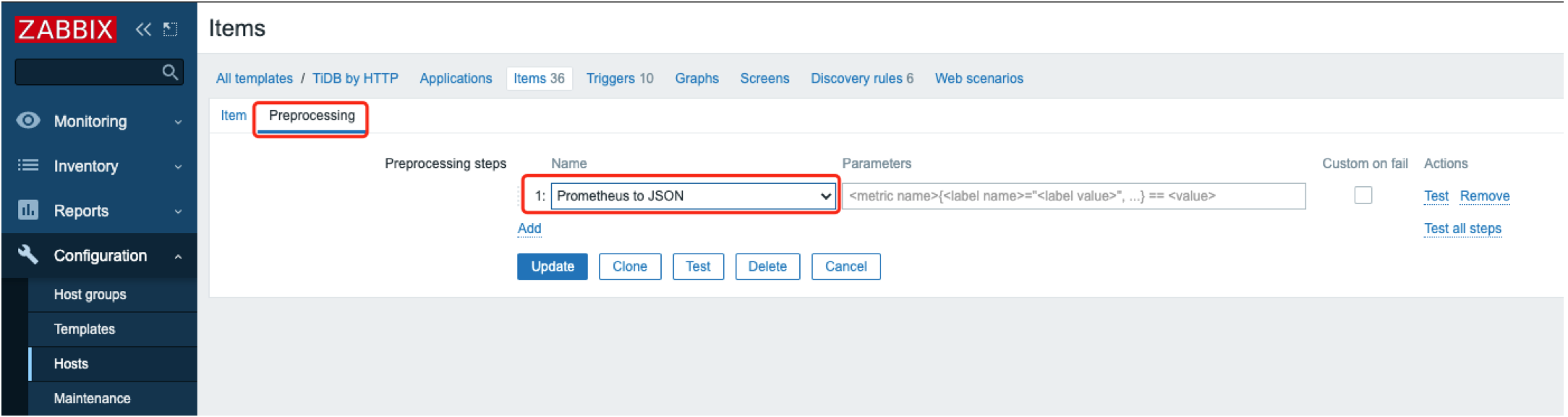
-
创建普通 item
因为 master item 获取的是所有 metrics,所以需要创建子 item 从 master item 中取出单个 metrics:
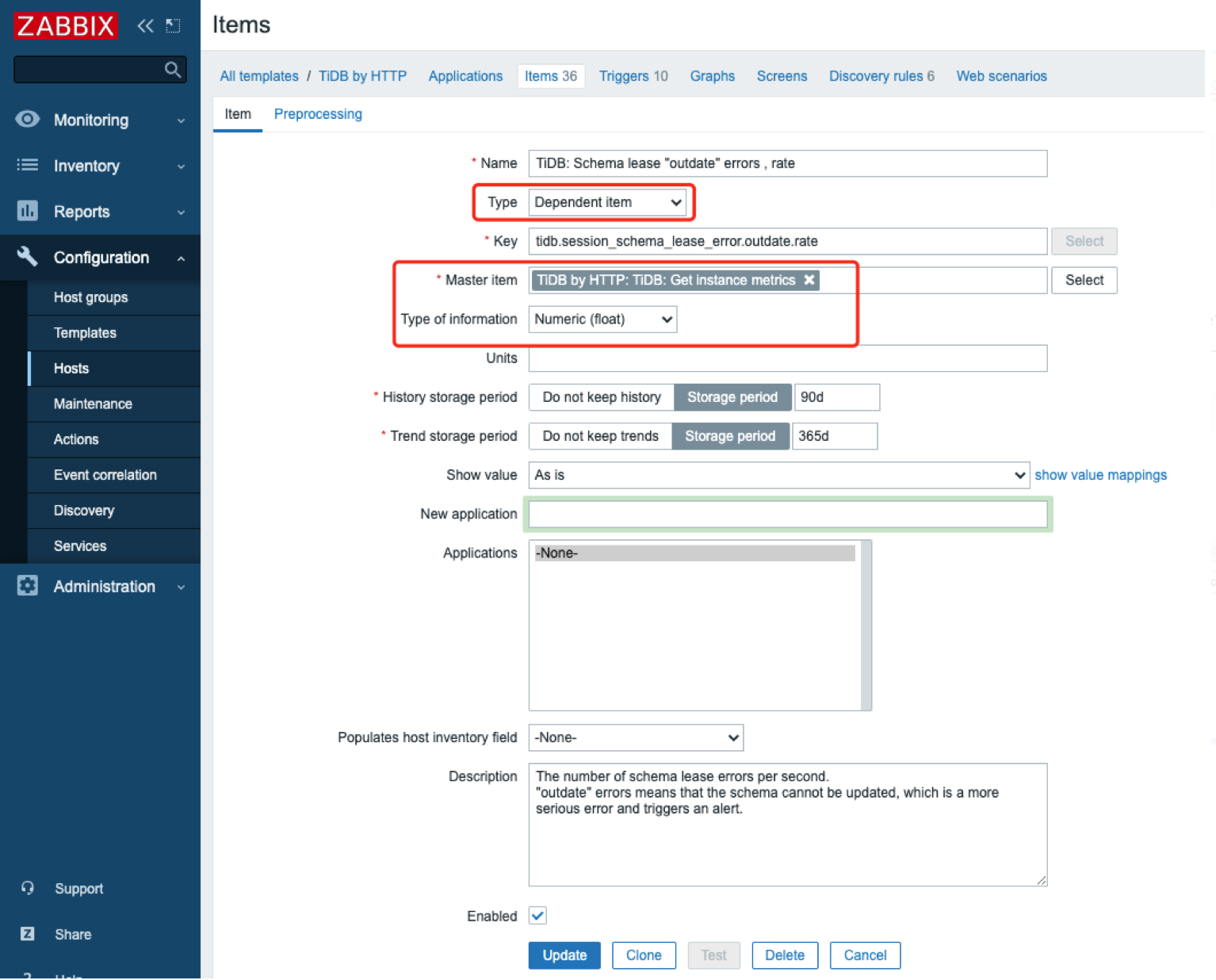
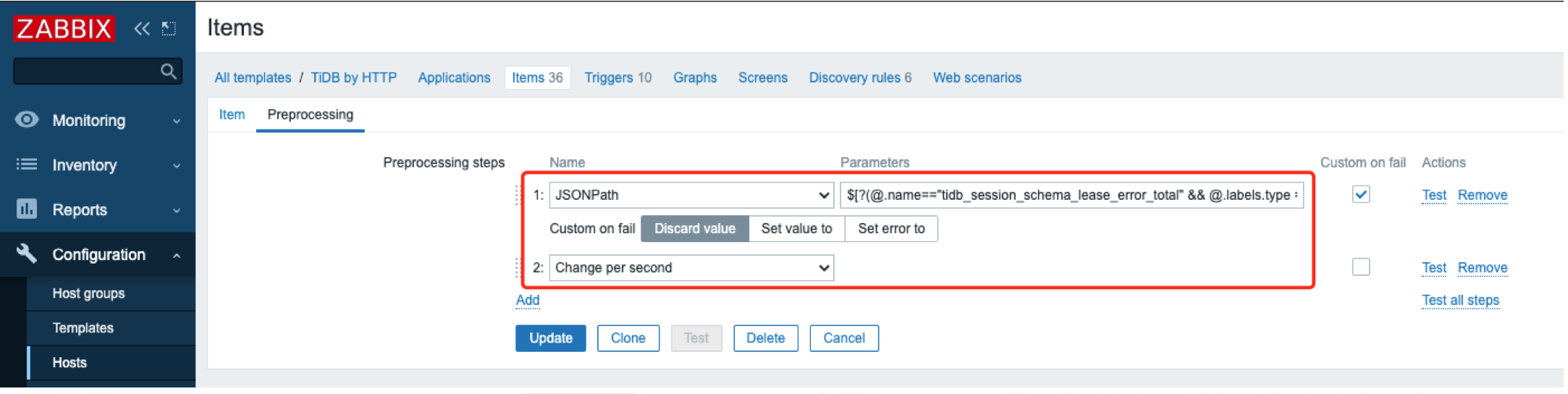
关键在于 “Preprocession”(数据预处理)中定义JSONPath,如下图所示:
-
JSONPath 表达式: $[?(@.name=="tidb_session_schema_lease_error_total" && @.labels.type == "outdated")].value.first()表示取 metric name 为 tidb_session_schema_lease_error_total 并且其 tpye 标签为 “outdated” 的值。注意:5.4的模板中的这个表达式是错误的,可以用 test 功能检测。 -
因为这个 metric 的类型是 Counter(累计值),所以用”Change per second”方法取得其平均每秒的增长值(注意:这是个平均值)。如果类型是 Gauge(瞬时值)就不需要这步处理了。
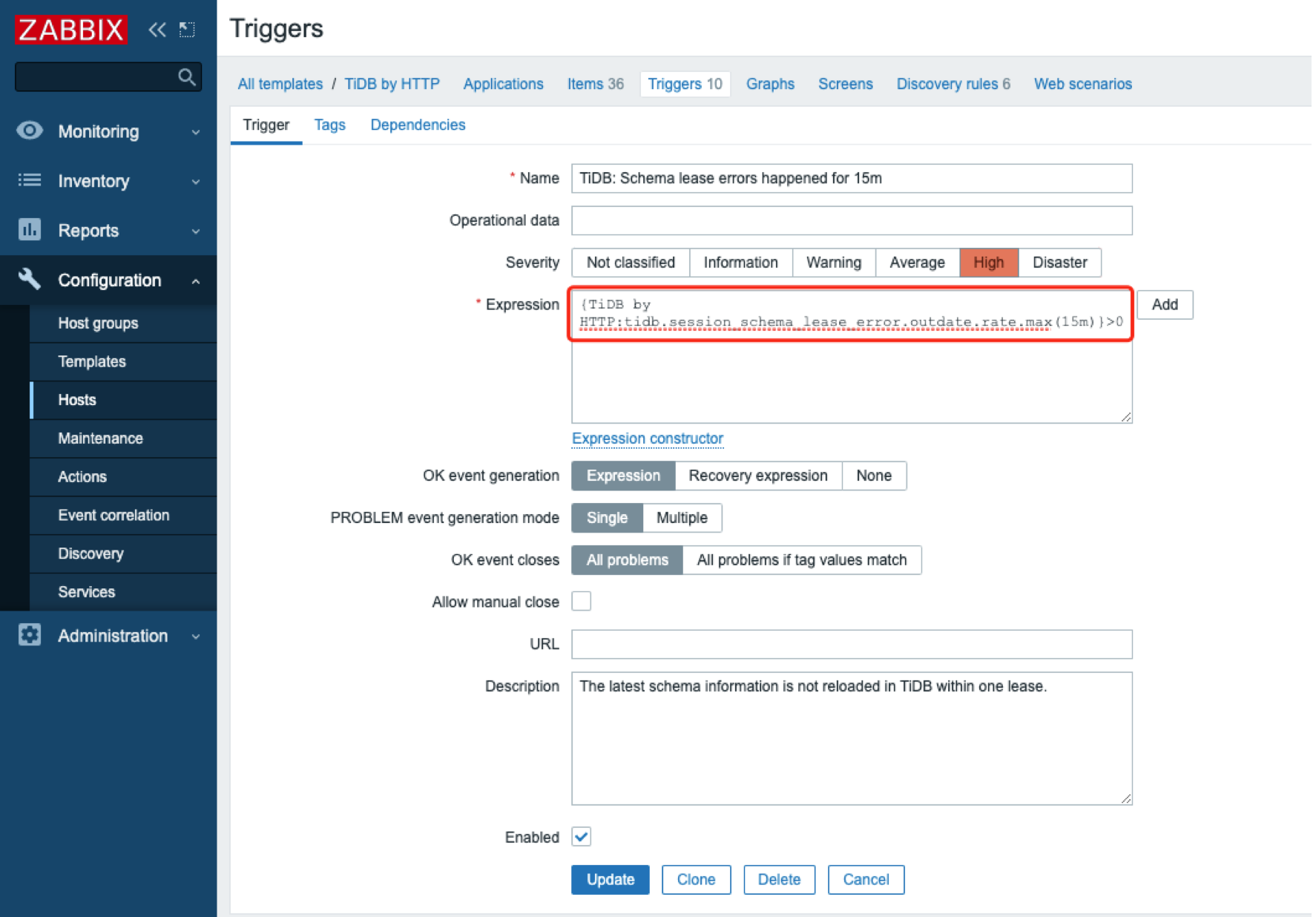
创建 trigger
trigger 就是定义当指定 item 的值达到什么条件,就触发其状态变成异常。先参考 TiDB 官方告警规则 的 Prometheus 语法:
increase(tidb_session_schema_lease_error_total{type="outdated"}[15m]) > 0
increase([15m]) 函数表示在15分钟内的增长值,整个表达式含义:为 15分钟内的增长大于 0。由于我们在 item 中定义的是 tidb_session_schema_lease_error_total 每秒增长量,所以当一段时间内平均每秒增长量的最大值大于0时,说明发生了error,就需要触发告警,触发器表达式为:
{TiDB by HTTP:tidb.session_schema_lease_error.outdate.rate.max(15m)}>0
附录
数据预处理-JSONPath
示例数据:
[
{
"name": "tidb_server_handle_query_duration_seconds_sum",
"value": "100",
"line_raw": "tidb_server_handle_query_duration_seconds_sum{sql_type=\"Begin\"} 0",
"labels": {
"sql_type": "Begin"
},
"type": "untyped"
},
{
"name": "tidb_server_handle_query_duration_seconds_sum",
"value": "50",
"line_raw": "tidb_server_handle_query_duration_seconds_sum{sql_type=\"Commit\"} 0",
"labels": {
"sql_type": "Commit"
},
"type": "untyped"
}
]
表达式:$[?(@.name=="tidb_server_handle_query_duration_seconds_sum")].value.sum()
含义:所有命令的总耗时
测试结果:150
表达式:$[?(@.name=="tidb_server_handle_query_duration_seconds_sum" && @.labels.sql_type=="Commit")].value.first()
含义:所有 Commit 命令的总耗时
测试结果:50
表达式:$[?(@.name=="tidb_server_handle_query_duration_seconds_sum" && @.labels.type =~ "Begin|Commit")].value.sum()
含义:所有 Begin、Commit 命令的总耗时(其他类型的不计算)
测试结果:150
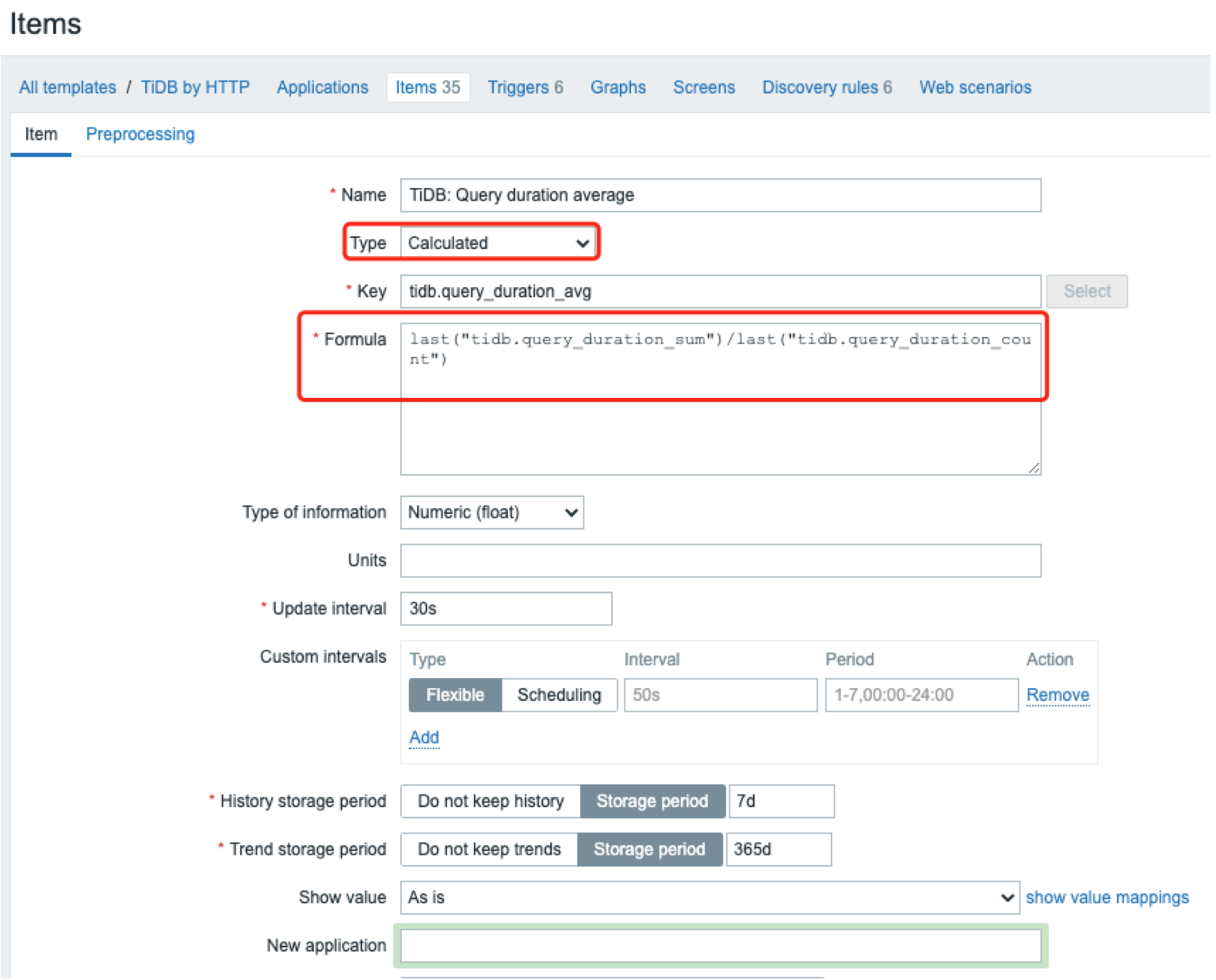
可计算item
文档:https://www.zabbix.com/documentation/5.0/zh/manual/config/items/itemtypes/calculated
基于其它监控项来创建可计算监控项,指定新创建的 item 为 “Calculated” 即可,以下示例先创建了两个 item:query_duration_sum、query_duration_count,两者相除得到Query的平均响应时间:
Trigger表达式技巧
1.内存使用量
表达式:
{TiDB by HTTP:tidb.heap_bytes.min(5m)}>{$TIDB.HEAP.USAGE.MAX.WARN}
含义:
tidb.heap_bytes是 key 名,对应的是TiDB监控中的 go_memstats_heap_inuse_bytes 指标,这是个 Gauge 类型(即瞬时值);
5分钟内,使用的内存最小值超过指定阈值(也就是持续5分钟内,使用的内存都超过了阈值),就报警
2.99响应时间
如何计算99%的SQL的响应时间?
TiDB监控接口提供的是直方图数据,类型为 histogram,prometheus 可以用 histogram_quantile()函数处理:
histogram_quantile(0.99, sum(rate(tidb_server_handle_query_duration_seconds_bucket[1m])) BY (le, instance)) > 1
但是 zabbix 处理不了,可以计算平均响应时间(用附录中的可计算item实现)。