一.中间件中的简单SQL
1.简单SQL的分类
在一般SQL中,一个单表查询的SQL往往是最简单的,而在中间件中也没什么区别,中间件中将一个对于单表的字段查询作为最简单的SQL进行处理。
2.中间件对于简单SQL的处理方式
下面先来简单的回顾下中间件中的表格处理的最基础方式。

中间件会按照在配置文件中既定的数据拆分的设置,对于“用户表”这个表格的数据进行拆分,将每条通过中间件插入的数据按照规则进行分布,图上给的例子是按照“用户表”的ID奇偶性进行了数据的拆分。
有了合理的数据分布之后就是中间件是如何在需要的时候取用数据的,在中间件中,对于基础SQL,也就是单表的数据查询分为一下两个情况:
- 带有分片信息的数据查询:下图展示了一个例子,在单表查询的过程中,如果存在影响数据分布的查询条件(在此例子中为用户的ID=1),
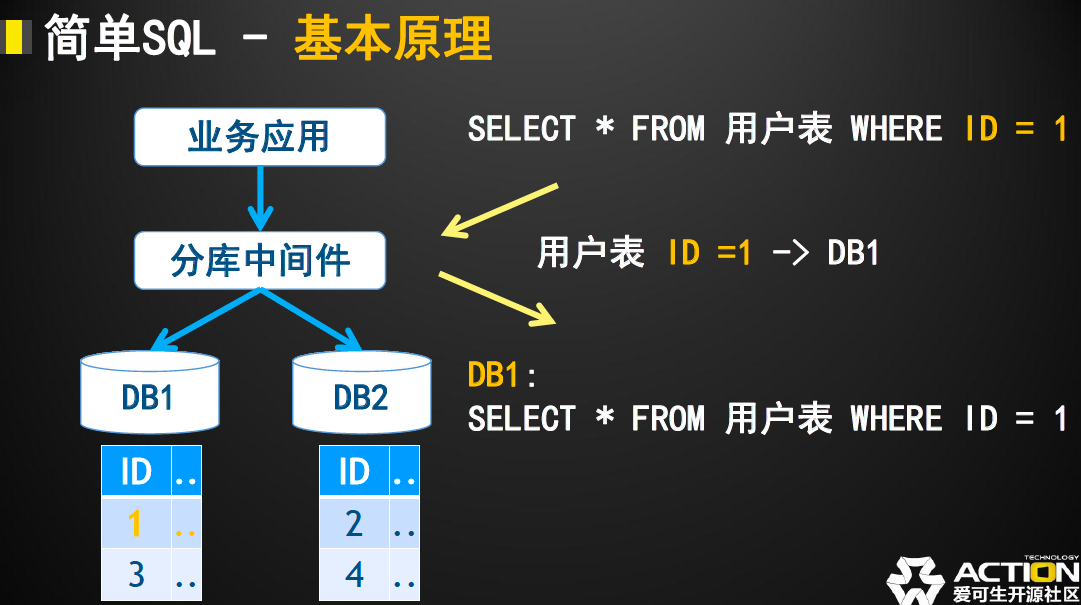
在查询的简单SQL附带有分片条件时,中间件根据SQL语义解析的结果,根据这个分片条件对于数据可能存在的DB进行计算,最终把SQL转发都对应的DB中进行执行,查询出最终的正确结果。
- 不带有分片信息的数据查询(广播):当查询的SQL不带有分片条件时,中间件只好把SQL内容发送到表格涉及到的所有DB中,并从每个DB中返回数据并整合.
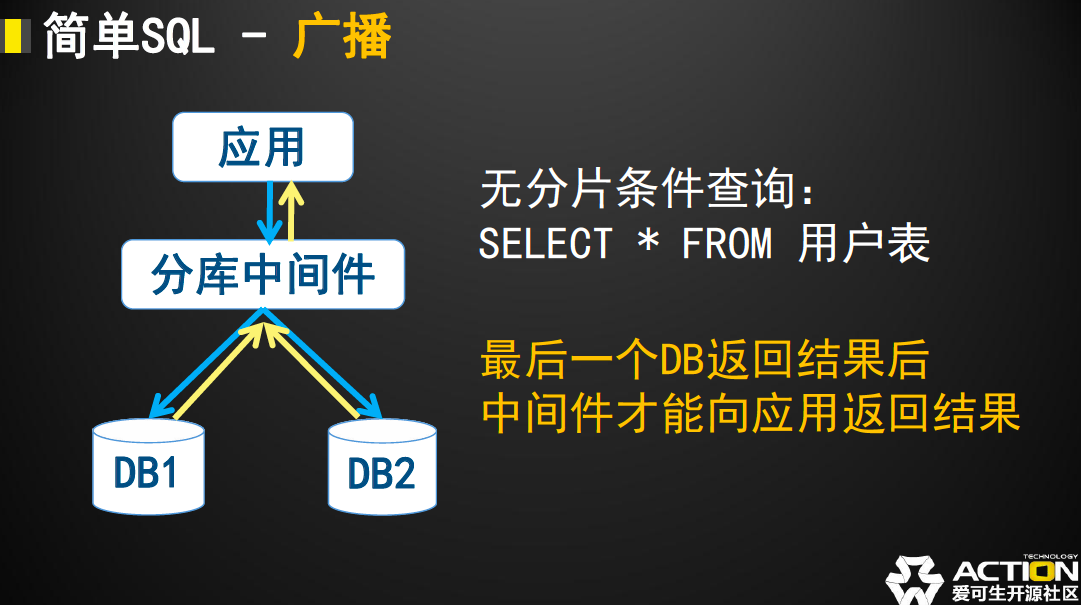
在这个过程中就存在一个现象,即“这一个查询需要等待最慢的那个DB查询结束”。
3.简单SQL的注意事项
上文中有提及广播类型的简单SQL存在一个特征“需要等待最慢的那个DB查询结束”,当分片数量持续上升的时候,如下图所示的场景,需要等待的连接数量会持续变多。

可以通过概率的方法分析下当连接数量增长的时候会发生什么变化:
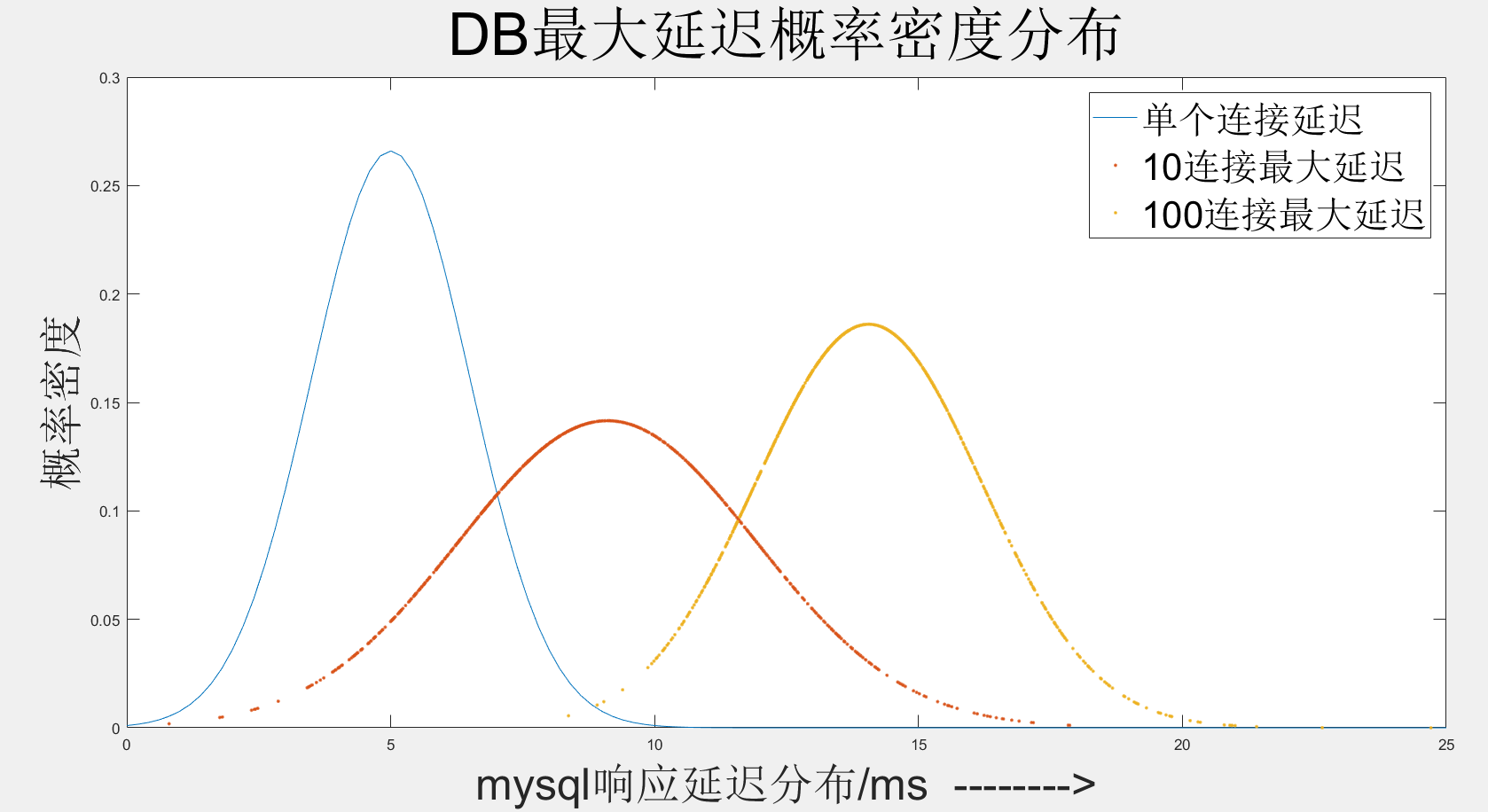
通过Matlab对于中间件广播查询的场景进行了如下的模拟,可以发现在随着需要等待连接数量的上升,整体的中间件响应速度会有一个成倍的下降,从单个连接平均5ms的查询延迟一直上升到100连接时候的接近15ms的整体延迟。
针对以上的场景,提出在中间件中进行单表查询的时候,尽量降低单个SQL涉及到的后端DB数量,具体方法时在SQL中给表格添加分片列的限定条件,就像select * from 用户表 where ID = 1中的这个条件ID =1。
二.中间件中的ER表格JOIN
1.中间件中ER关系的定义
单表查询不能覆盖应用对于SQL的需求,中间件中就引入了ER关系的概念。
ER关系指的是两个表格在逻辑上就拥有的从属关系,如下图中所示的用户表和订单表:

当两个表或者更多的表格存在这样逻辑上的从属关系的时候,在中间件中把这些关系定义为ER关系,并且当一个查询语句有且仅有存在ER关系的表格关联组成的时候,这个SQL被称为“ER表格JOIN”。
2.中间件对于ER表格JOIN的处理方式
当两个表格能够被定义为ER关系的时候,中间件能够按照之间的关联关系组织数据的存储,最后的存储方式如下图所示:
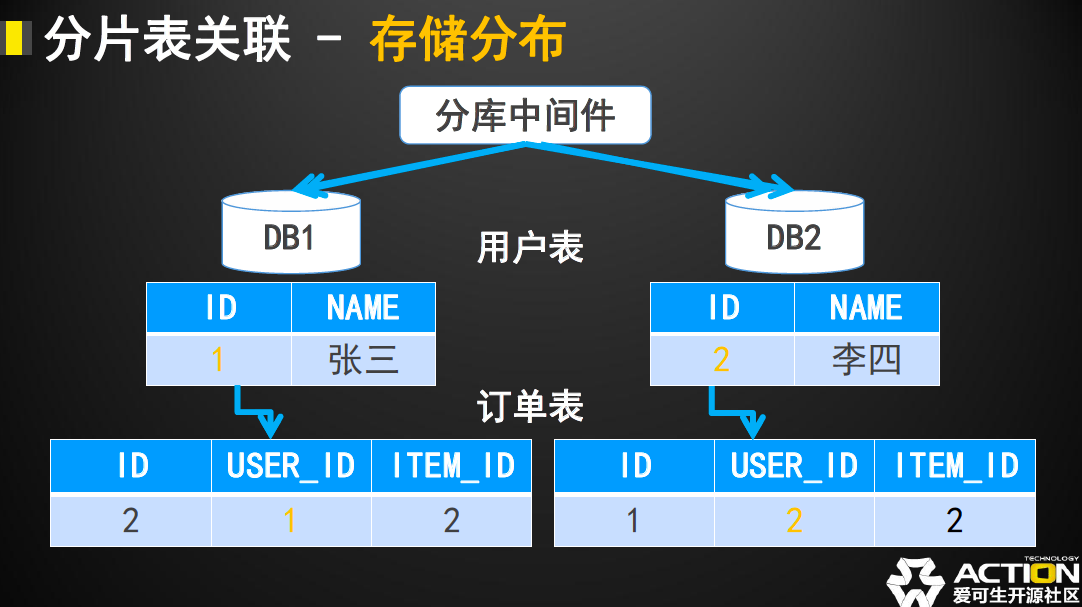
可以看到大致的结果就是子表(订单表)的数据会被存放在父表(用户表)对应数据的DB节点。
当出现这种数据分布的时候,就可以在DB1中查询到上例中张三的用户和他的所有数据,所以中间件就能直接把SQL语句下发到对应节点进行执行。
3.ER关联SQL的注意事项
可以看到ER的这种查询方式是有一定的局限的,需要把查询的表格声明为ER关系,并且ER关系还是单向的,就是一个表只能是某一个表的子表,一个分片表不能拥有两个父表。
其次就是由于这个ER关联的查询处理是和上文的简单查询在本质上是一样的,就是查询SQL下发到DB中来执行,所以在注意事项上也是一致的,尽量在使用的时候提供能够确定分片的限定条件。
三.中间件中的跨库表格JOIN
1.跨库表格JOIN的定义
事实上上文所有的查询方法限制都是非常大的,但是往往应用的SQL无法满足于被限制在这么局限的范围内,那中间件中就有另一种机制来实现更广泛意义上的SQL执行,跨库表格关联查询.
当我的SQL内容无法被定义进入上文的两个“简单SQL”或者是“ER SQL”的时候,中间件就会使用这种跨库表格JOIN的方式来处理这个问题,当然并非所有的中间件都有实现对应的功能,在这里仅讨论实现的部分中间件的实现逻辑.
2.中间件中跨库表格JOIN的执行
以下是在中间件中执行跨库表查询的这么一个大致执行逻辑图,图中可以看到整体的执行逻辑是从每个DB中分别取TABLE_A和TABLE_B的数据,最终在中间件中进行数据的整理组织和对比:
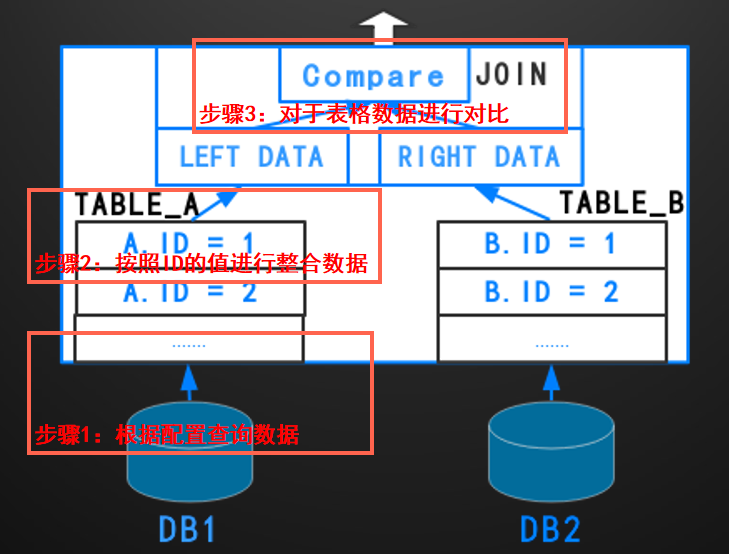
具体的跨库查询的执行过程可以被归纳为以下的几个步骤:
– 根据配置文件中对于TABLE_A和TABLE_B的描述将表格的数据分别从DB中进行查询
– 对于查询得到的表格数据进行整理,分别按照ID的值(关联列的值)进行排序和归档
– 对于归档完成的数据进行ID值的对比,计算关联结果
那在这个过程中会产生几个方面的资源消耗:
– 组织数据产生的临时内存存储消耗
– 对比数据产生的CPU消耗
– 查询每一个存在DB中的表数据产生的连接数以及网络消耗
另一个方面就是中间件由于不能存储真实的数据,所以无法像MySQL优化器一样提前计算不同表格的聚合代价,这么一来,中间件就直接按照SQL中原有的表格聚合顺序进行数据的聚合和整理,这可能带来以下的SQL执行的计划。
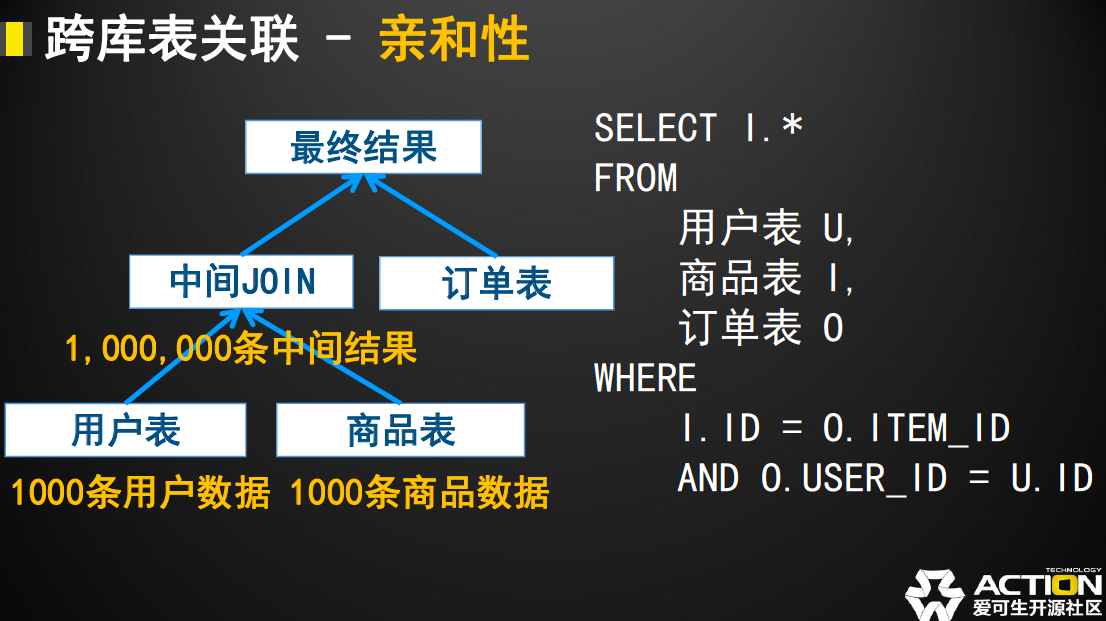
案例中用户表由于表格顺序的问题先和没有直接关系的商品表进行了表关联,这样一来这里的中间结果就出现了一个笛卡尔积,也就是无条件无字段的关联结果,其结果为双边数据的乘积:1000X1000=1000000;
如果SQL中的表格顺序进行进一步的优化,则可以在同样的SQL中获得以下图中的执行顺序。
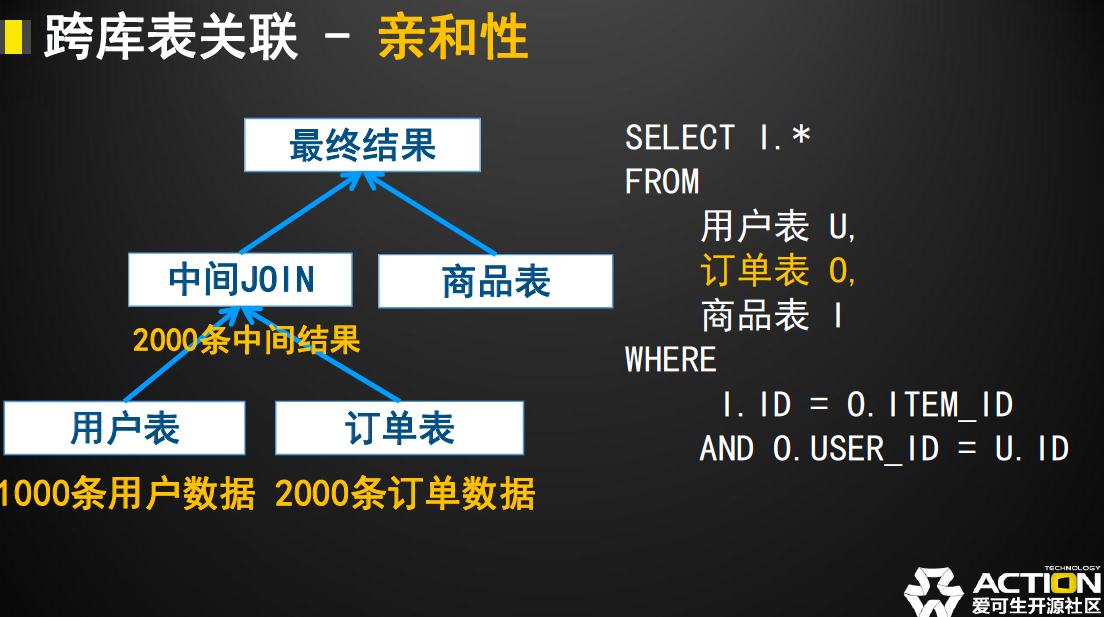
这次我们优化完成之后的查询中间结果将由用户表和有关系的订单表优先聚合完成,因为他们之间的关系,最多存在2000条中间结果,相比与上例中的1000000条来说,整个SQL执行效率上得到了很大的优化。
3.跨库JOIN的注意事项
那针对以上的几种消耗类型,可以通过以下的几个手段进行降低消耗的量以获取最好的执行效果:
– 添加足够的限定条件
– 使用重复率低的列进行关联
– 通过手动调整SQL中表格顺序的手段来进行执行计划的调整
四.通篇总结
从DB存储到真正成熟的分布式DB,分布式中间件的架构是整个过程中的重要一环,在分布式架构的过程中,对SQL的规范和使用存在一些特别要求,应用在向这方面进行改造和适应的过程中需要更多的考虑到中间件架构带来的限制及相关注意事项。整体归纳可分为以下内容:
1.在中间件中尽量使用分片条件进行数据的查询,不论整个SQL是属于简单SQL,ER查询或者是复杂查询
2.在复杂查询的状态下,优化方向为中间件中处理的数据尽量少,此目标可以通过给表格添加限定条件,选择更加重复率低的关联列以及调整SQL中的表格关联顺序来达成
开源分布式中间件DBLE
社区官网:https://opensource.actionsky.com/
GitHub主页:https://github.com/actiontech/dble
技术交流群:669663113
开源数据传输中间件DTLE
社区官网:https://opensource.actionsky.com/
GitHub主页:https://github.com/actiontech/dtle
技术交流群:852990221
