作者:张强
爱可生研发中心成员,后端研发工程师,目前负责DMP产品 Redis 相关业务开发。
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
一. 什么是 Kubernetes ?
Kubernetes,又称为 k8s(首字母为 k、首字母与尾字母之间有 8 个字符、尾字母为 s,所以简称 k8s )或者简称为「kube」,是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务。相比与传统部署以及虚拟化部署方式而言,具有如下特点:
-
敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。 -
持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性),支持可靠且频繁的 容器镜像构建和部署。 -
关注开发与运维的分离:在构建/发布时而不是在部署时创建应用程序容器镜像, 从而将应用程序与基础架构分离。 -
可观察性:不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。 -
跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。 -
跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。 -
以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。 -
松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 – 而不是在一台大型单机上整体运行。 -
资源隔离:可预测的应用程序性能。 -
资源利用:高效率和高密度。
1. Docker 的兴起
要说 Kubernetes,还要从 docker 容器化技术谈起。
2013年,Docker 公司(彼时还称之为 dotCloud Inc.)在 PyCon 大会上首次公开介绍了 Docker 这一产品。当时最热门的 PaaS 项目是 Cloud Foundary,然而 Docker 项目在 docker 镜像上的优秀设计,解决了当时其他 PaaS 技术未能解决的应用打包和应用发布的繁琐步骤问题。大多数 docker 镜像是直接由一个完整操作系统的所有文件和目录构成的,所以这个压缩包里的内容跟你本地开发和测试环境用的操作系统是完全一样的 —— 正是这一优秀的特性使得 docker 项目在众多 Pass 技术迅速崛起。
2. Docker 编排的进化
Swarm 的最大特点,是完全使用 Docker 项目原本的容器管理 API 来完成集群管理。在部署了 Swarm 的多机环境下,用户只需要使用原先的 Docker 指令创建一个容器,这个请求就会被 Swarm 拦截下来处理,然后通过具体的调度算法找到一个合适的 Docker Daemon 运行起来。
2014年,docker 并购 Fig 项目,将其发展为现在的 Compose,使得容器的部署更加的便利 —— 可以使用配置文件就可以完成较为复杂的容器的编排参数的配置。同年6月,Google 公司发布了 Kubernetes。
2015 年 6 月 22 日,由 Docker 公司牵头,CoreOS、Google、RedHat 等公司共同宣布,Docker 公司将 Libcontainer 捐出,并改名为 RunC 项目,交由一个完全中立的基金会管理,然后以 RunC 为依据,大家共同制定一套容器和镜像的标准和规范。这套标准和规范,就是 OCI( Open Container Initiative )。OCI 的提出,意在将容器运行时和镜像的实现从 Docker 项目中完全剥离出来。从 API 到容器运行时的每一层,Kubernetes 项目都为开发者暴露出了可以扩展的插件机制,鼓励用户通过代码的方式介入到 Kubernetes 项目的每一个阶段。Kubernetes 项目的这个变革的效果立竿见影,很快在整个容器社区中催生出了大量的、基于 Kubernetes API 和扩展接口的二次创新工作,比如:
-
微服务治理项目 Istio; -
有状态应用部署框架 Operator; -
还有像 Rook 这样的开源创业项目,它通过 Kubernetes 的可扩展接口,把 Ceph 这样的重量级产品封装成了简单易用的容器存储插件。
二. Docker 容器的技术基础
1. 进程与 Linux Namespaces
为了达到在容器中排除其他进程,docker 利用了 Linux 的 Namespace 机制。在 Linux 系统中创建线程的系统调用是 clone(),比如:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
此时,这个系统调用就会为我们创建一个新的进程,并且返回它的进程号 pid。而如果在用 clone() 系统调用创建一个新进程时,加入 CLONE_NEWPID 参数,比如:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
此时这个进程就会在一个全新的进程空间里,在这个进程空间里,它的 pid 是1。 除去 PID Namespace,Linux 系统还提供了 Mount、UTS、IPC、Newwork 和 User 等 Namespace。这就是为什么容器中只能「看到」自身容器内的进程的原因了。
2. 资源限制与Linux Cgroups
虽然在容器中 PID 为1的进程只能看到容器里的情况。但是从宿主机角度来看,它作为一个普通进程与其他进程依然是平等关系,也就说它能够使用的资源(CPU、内存等),仍旧可以被宿主机上的其他进程占用。这种情况导致了容器内的进程「隔离了但没有完全隔离」的尴尬,是不符合容器作为一个「沙盒」的特性的。
Linux Cgroups 的全称是 Linux Control Groups。它的最主要作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等。比如:
-
blkio,为块设备设定 I/O 限制,一般用于磁盘等设备; -
cpuset,为进程分配单独的 CPU 核和对应的内存节点; -
memory,为进程设定内存使用的限制。 等等
凭借 Cgroups 的机制,容器化技术可以完成对容器内进程的资源限制。
3. 容器镜像和文件系统
Linux 操作系统中有一个名为chroot的命令,作用就是改变进程的根目录到指定的位置。比如执行chroot $HOME/test /bin/bash之后,如果执行ls /,就会看到命令返回的内容都是 $HOME/test 目录下的内容。Linux 操作系统的第一个 Namespace 是 Mount Namespace,正是基于 chroot 的不断改良而来的。
为了让容器中的目录看起来更「真实」,一般会在容器内的根目录下挂载一个完整操作系统的文件系统。比如 Ubuntu 16.04 的 ISO。这样在启动容器后,在容器内执行ls /查看根目录下的内容,就是 Ubuntu 16.04 的所有目录和文件。这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的「容器镜像」,也称之为 rootfs (根文件系统)。
所以,对于 Docker 来说,核心流程即:
-
启用 Linux Namespace 配置; -
设置指定的 Cgroups 参数; -
切换进程的根目录(pivot_root 或 chroot)。
同时需要注意:rootfs 只是一个操作系统所包含的文件、配置和目录,并不包含 Linux 操作系统内核。所有的容器,都共享宿主机操作系统的内核。
综上,一个「容器」,实际上是一个由 Linux Namespace、Linux Cgroups 和 rootfs 三种技术构建出来的进程的隔离环境。可以分为两部分:
-
容器镜像,即联合挂载在 /var/lib/docker/aufs/mnt 上的 rootfs。 -
容器运行时,即一个由 Namespace + Cgroups 构成的隔离环境。
三. Kubernetes 架构简介
从一个开发者的角度来说,真正需要关注的是容器镜像。从容器集群管理角度来说,而能够定义容器组织和管理规范的「容器编排」技术是最重要的。其中最具代表性的容器编排工具,当属 Docker 公司的 Compose+Swarm 组合,以及 Google 与 RedHat 公司共同主导的 Kubernetes。
Kubernetes 脱胎与 Google 内部的 Borg 项目。而 Borg,是承载 Google 公司整个基础设施的核心依赖。在 Google 公司已经公开发表的基础设施体系论文中,Borg 项目当仁不让地位居整个基础设施技术栈的最底层。同时在开源社区的努力下,Kubernetes 又修复了原来 Borg 体系中的缺陷和问题。借着 Borg 项目的理论优势,逐步确定了一个如下图所示的全局架构:
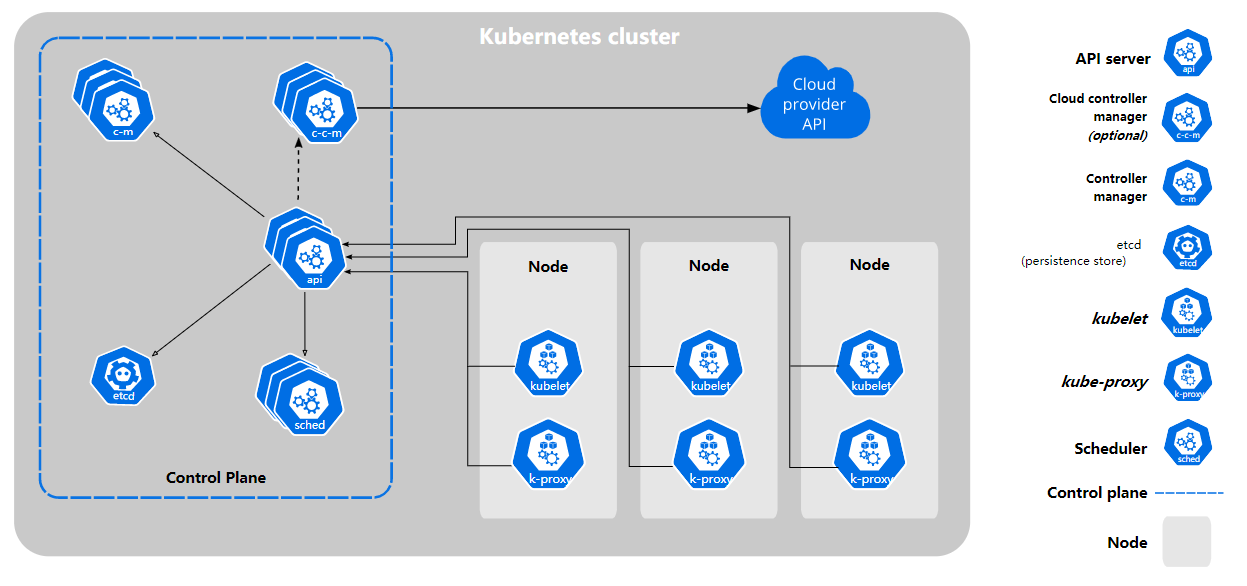
Kubernetes 项目的架构,都由 Master 和 Node 两种节点组成,分别对应着控制节点和计算节点。其中:
-
Master 控制节点 -
负责 API 服务的 kube-apiserver; -
负责调度的 kube-scheduler; -
负责内容编排的 kube-controller-manager; -
负责集群持久化数据的 etcd 。
-
-
Node 计算节点 -
负责与容器运行时交互的 kubelet 组件。另外,还为容器配置网络和持久化存储; -
负责维护节点上的网络规则 kube-proxy 。 -
容器运行时,Kubernetes 支持 Docker、containerd、CRI-O 等多个容器运行环境。
-
以上设计的考量是 Kubernetes 没有把 Docker 作为架构的核心,而仅仅把 Docker 作为一个底层的容器运行时实现。Kubernetes 最核心的问题是:运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系。这些关系的处理,才是作业编排和管理系统最困难的地方。
在一个稍复杂的集群系统中,会有各种不同的服务关系存在,比如:一个 Web 应用与数据库之间的访问关系,一个计算服务和监控套件之间的访问关系等。在容器技术普及之前,处于部署上的便利,这些应用可能会被部署在同一台虚拟机中。在容器技术出现后,原本的各个应用、组件、守护进程,都可以被分别做成镜像并且运行在每个专属的容器中。它们之间互不干涉,拥有各自的资源配额,可以被调度在整个集群的任何一台机器上。
为了更好地处理容器间应用的访问关系,连接紧密的容器会被划分为一个「Pod」,Pod 里的容器共享同一个 Network Namespace、同一组数据卷等。同时 Kubernetes 会给 Pod 绑定一个 Service 服务(kube-proxy),主要作用是作为 Pod 的代理入口,从而代替 Pod 对外暴露一个固定的网络地址。
Kubernetes 还定义了基于 Pod 改进后的对象。比如用 Job 来描述一次性运行的 Pod;用 DaemonSet 来描述有且只有一个副本的守护进程;又比如 CronJob,用于描述定时任务。
Kubernetes 使用声明式 API 方式来编排应用。所谓声明式,就是提交一个定义好的 API 对象来「声明」,表示所期望的最终状态即可。如果提交的是一个个命令,去一步一步达到期望状态,这就是「指令式」。比如,使用 kubernetes 来启动一个 Nginx 容器镜像,具体步骤为:
-
编写一个名为 nginx-deployment.yaml 文件,定义一个 Depoloyment 对象。主体是一个使用 Nginx 镜像的Pod,可以定义副本数为 2 (replicas=2); -
执行命令 kubectl create -f nginx-deployment.yaml来启动容器。
从设计目标来看, Kubernetes 提供了一套基于容器的、能够便利地构建分布式系统的基础依赖,能够完成容器应用的部署以及应用的弹性管理。它所擅长的,就是按照用户的定义和系统规则,来自动处理容器(应用/服务)之间的各种关系。而这一切,都是基于容器化技术来实现的。至于更进一步的学习 Kubernetes 架构相关知识,以及 Kubernetes 环境下的环境开发,请见后续相关文章更新。
四. 参考
[1] 维基百科:Kubernetes 词条 (https://zh.wikipedia.org/wiki/Kubernetes)
[2] Kubernetes 官方文档 (https://kubernetes.io/)
[3] 深入剖析Kubernetes (https://time.geekbang.org/column/intro/100015201)
[4] 维基百科:Linux namespaces 词条 (https://en.wikipedia.org/wiki/Linux_namespaces)
[5] 维基百科:Cgroups 词条 (https://zh.wikipedia.org/wiki/Cgroups)